1.
Introduction
Considérons une liste de nombres quelconques, par exemple
(3 6 5.5 12 -2 0 7 89 36)
La question est, non pas "trouver le minimum de cette liste"
(n'importe qui en est capable), mais : "expliquer à une machine comment
trouver le minimum de n'importe quelle liste de nombres". En essayant de
concilier quatre impératifs :
- lui expliquer suffisamment bien pour qu'elle trouve, quelle que soit la liste
- que l'explication soit aussi courte que possible
- que la machine trouve le plus vite possible
- qu'elle trouve en utilisant aussi peu de place que possible
Le premier point suppose l'existence d'un langage
commun entre la machine et nous. Dans ce cours, le langage sera Scheme.
Il suppose d'autre part que l'on sache faire la preuve que ce que
l'on écrit dans ce langage mène à tout coup à la solution. Dans ce cours, ce
problème sera laissé de côté.
Le deuxième point relève de l'art de la programmation : cela ne
s'enseigne pas, ça s'apprend sur le tas (mais ce cours va vous y aider).
Les deux derniers points introduisent la notion de complexité,
qui sera régulièrement évoquée dans ce cours, et développée par la suite.
1.1.
Notion d'algorithme
Si je suis obligé de rester à côté de la machine pendant
qu'elle travaille, j'aurais plus vite fait de faire le travail moi-même ; donc
il faut que je puisse lui décrire à l'avance ce que j'attends
d'elle, et que je passe moins de temps à cette description qu'il ne m'en
faudrait pour exécuter le travail.
Si je dois redécrire le travail chaque fois qu'il change un peu (par exemple si
je demande le minimum d'une liste différente de la première), même chose ; donc
il faut que la méthode que je lui donne soit suffisamment générale.
On appelle algorithme une méthode :
- suffisamment générale pour pouvoir traiter, non pas un problème, mais une classe de problèmes
- combinant des opérations suffisamment simples pour être effectuées par une machine
1.2.
Architecture
D'après ce qui a été dit plus haut, cet algorithme doit
pouvoir être stocké dans la machine, pour que je puisse aller
faire autre chose. Il faut donc que la machine ait une mémoire.
Il doit d'autre part pouvoir traiter des problèmes (légèrement) différents les
uns des autres, donc il faut qu'on puisse fournir les problèmes ; c'est ce que
nous appellerons les données (entrées : input), qui doivent,
elles aussi, pouvoir être stockées.
S'il trouve la solution mais ne peut pas me l'indiquer, cela ne sert à rien ;
il faut qu'il puisse la faire sortir (output), sur écran, sur
papier, ou tout autre support.
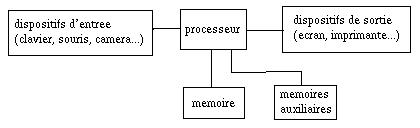
D'où l'architecture (ultra-simplifiée) de la machine : 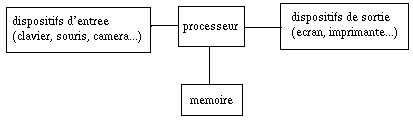
Mais la mémoire est volatile, c'est-à-dire qu'elle peut être
réutilisée par une autre application. J'ai donc également besoin de mémoires
plus stables, par exemple des disques ou des disquettes, sur lesquelles je
conserverai longtemps mes programmes, mes données, voire les résultats que j'ai
obtenus.
1.3.
Structure de la mémoire
|
|
La mémoire peut être vue comme un tableau à une dimension
(vecteur). Chaque case de ce tableau, appelée mot, est
composée, sur la plupart des machines actuelles, de 32 bits,
c'est à dire 4 octets (groupe de 8 bits). Un bit est l'unité
minimale d'information : il ne peut être que dans l'un de deux états. La
taille de la mémoire se mesure, pour des raisons historiques, en nombre
d'octets (diviser par 4 pour avoir le nombre de mots). Les unités
traditionnelles sont le ko (1 kilo-octet = 210 =
1024 octets), le Mo (1 méga-octet = 1024 ko), et le Go
(giga-octet). |
1.4.
Représentations en mémoire
|
|
Un mot-mémoire est constitué de 32 bits, certains dans l'état E1, les autres dans l'état E2. Le reste n'est que convention.
|
1.5.
Structure des mémoires auxiliaires
Les mémoires
auxiliaires ont la même structure que la mémoire centrale (vecteur de mots de
32 bits). Mais on plaque par dessus une nouvelle structure : on découpe la
mémoire en fichiers.
Un fichier (en anglais : file) est une zone de la mémoire qui porte un nom. Par
exemple, ce que vous êtes en train de lire est le contenu du fichier main.html
.
On structure les fichiers en les regroupant dans un répertoire.
Un répertoire (en anglais : directory) est un ensemble de fichiers. Un répertoire
peut aussi contenir des répertoires. On obtient une structure arborescente. 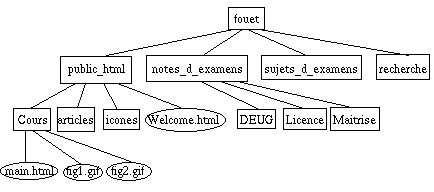
2-Mon
premier algorithme
Reprenons le problème posé en introduction. Soit à déterminer le minimum d'une liste de nombres, par exemple (3 6 5.5 12 -2 0 7 89 36).
2.1.
Algorithme itératif
![]() Je
parcours la liste de gauche à droite, en retenant à chaque pas le minimum
"pour l'instant". Je fais donc une boucle, dans la
mesure oû je fais la même chose sur chaque case du tableau.
Je
parcours la liste de gauche à droite, en retenant à chaque pas le minimum
"pour l'instant". Je fais donc une boucle, dans la
mesure oû je fais la même chose sur chaque case du tableau.
- entre 3 et 6, c'est 3
- entre 3 et 5.5, c'est 3
- entre 3 et 12, c'est 3
- entre 3 et -2, c'est -2 (j'efface 3 de ma mémoire, je mets -2 à la place)
- entre -2 et 0, c'est -2
- etc
A la fin, dans ma mémoire, il y a -2.
2.2.
Bilan
J'ai utilisé, outre les 9 mots dans lesquels j'ai stocké la liste :
- un mot pour stocker le "minimum pour l'instant"
- un mot pour savoir où j'en étais dans ma liste (adresse)
- un mot pour la longueur de la liste (pour savoir quand m'arrêter)
Voilà pour l'espace. En ce qui concerne le temps, j'ai fait :
- une affectation initiale (j'ai mis 1 dans le mot "adresse dans la liste")
- une affectation initiale (j'ai mis 3 dans le mot "mini pour l'instant")
- 8 comparaisons (entre un mot de la liste et le mot "mini pour l'instant")
- 1 affectation (j'ai remplacé 3 par -2)
- 9 incrémentations (j'ai ajouté 1 à l'adresse)
- 9 comparaisons (entre l'adresse courante et la longueur de la liste)
![]() Si
la liste avait été différente (mais de même longueur), j'aurais eu exactement
les mêmes nombres d'opérations, SAUF pour les affectations au mot "mini
pour l'instant", que je ne peux pas prévoir. On distingue alors
Si
la liste avait été différente (mais de même longueur), j'aurais eu exactement
les mêmes nombres d'opérations, SAUF pour les affectations au mot "mini
pour l'instant", que je ne peux pas prévoir. On distingue alors
- le meilleur cas : 0, si le premier nombre est le mini
- le pire cas : 8, s'ils sont rangés dans l'ordre décroissant
- le cas moyen : 4, la moyenne, s'ils respectent une distribution parfaitement aléatoire.
2.3.
Algorithme récursif
Dans ce cours, nous n'examinerons plus d'algorithme
itératif. Nous prenons une approche tout à fait différente.
![]() Supposons
le problème résolu pour la liste privée de son premier élément, c'est-à-dire
(6 5.5 12 -2 0 7 89 36).
Supposons
le problème résolu pour la liste privée de son premier élément, c'est-à-dire
(6 5.5 12 -2 0 7 89 36).
Je connais donc le minimum de cette sous-liste, appelons le M. Le minimum de la
liste complète s'obtient simplement par comparaison entre le premier élément de
la liste et M. Ici, entre 3 et -2, je prends -2.
Mais comment avons-nous résolu le problème pour la sous-liste? En faisant le
même raisonnement. C'est cela qu'on nomme récursivité.
Mais comment ça s'arrête? Quand on ne peut pas parler de sous liste,
c'est-à-dire quand la liste a pour longueur 1. Dans ce cas, le minimum est le
seul élément de la liste.
2.4.
Formalisation
minimum d'une liste si la liste n'a qu'un élément c'est l'élément de la liste sinon si le premier élément de la liste est plus petit que le minimum de la sous-liste obtenue en enlevant le premier élément c'est le premier élément de la liste sinon c'est le minimum de la sous-liste obtenue en enlevant le premier élément finsi finsifinminimum |
2.5.
Remarque : bugs
L'algorithme ci-dessus est très joli, mais il est FAUX!
Si la liste initiale est vide, je ne sais pas ce qu'il va faire ; peut-être
tourner en rond indéfiniment.
Si la liste contient des choses autres que des nombres, je ne sais pas non
plus.
Bien sur, vous me direz que ce sont des cas vicieux d'utilisation. Mais l'art
du programmeur est de penser à tout. Pour trouver les bugs, il va
- Définir son problème aussi bien que possible, c'est ce qu'on appelle la spécification
- Programmer proprement (notion à définir)
- Tenter de prouver que son programme répond à la spécification
- Passer des jeux d'essai, aussi divers et vicieux que possible
2.6.
Opérations élémentaires
Reprenons la formalisation du 2.4. De quoi avons nous besoin?
- test (si... sinon... finsi)
- longueur d'une liste
- premier élément d'une liste
- sous-liste obtenue en enlevant le premier élément
- plus petit que
- ... et de la manière de définir cet algorithme (minimum... finminimum)
3-Mon
premier programme
3.1. Notion
de fonction
Une fonction prend des arguments et renvoie un
résultat. Arguments et résultat ne sont pas nécessairement des nombres : ils
peuvent être de n'importe quel type : nombre (entier ou
flottant), booléen (c'est-à-dire "vrai" ou "faux"), caractère,
chaine de caractères, ou liste.
Les arguments peuvent être des constantes ou des symboles
à condition que le symbole ait une valeur. De plus, les arguments peuvent être
eux-mêmes des appels à des fonctions.
3.2.
Ecriture de l'appel à une fonction
Pour écrire un appel à une fonction, on doit respecter une
syntaxe : ![]()
- parenthèse ouvrante
- nom de la fonction
- blanc
- premier argument
- blanc
- deuxième argument, etc
- parenthèse fermante
On doit également respecter la sémantique ![]() de
la fonction, c'est-à-dire lui donner autant d'arguments qu'elle en nécessite,
et du bon type.
de
la fonction, c'est-à-dire lui donner autant d'arguments qu'elle en nécessite,
et du bon type.
Exemples :
(+ 5 13) ; renverra 18(- 10 a) ; renverra la différence si "a" a une valeur numérique, ; affichera une erreur sinon(+ (* 2 5) (- 3 1)) ; renverra 12(* 5) ; n'est pas correct(*5 2) ; non plus(/ 5 "a") ; non plus |
3.3.
Evaluation de l'appel à une fonction
![]() Lorsqu'on
lui fournit l'appel à une fonction, Scheme
Lorsqu'on
lui fournit l'appel à une fonction, Scheme
- évalue chacun des arguments, dans un ordre imprévisible, PUIS
- regarde s'il connait la fonction, sinon affiche un message d'erreur
- applique la fonction aux résultats de l'évaluation des arguments
- affiche le résultat
Le processus est donc éminement récursif.
![]() Dans
un premier temps, la plupart de vos bugs viendront de ce que vous aurez oublié
qu'il applique la fonction NON PAS aux arguments, mais au résultat de l'évaluation
des arguments.
Dans
un premier temps, la plupart de vos bugs viendront de ce que vous aurez oublié
qu'il applique la fonction NON PAS aux arguments, mais au résultat de l'évaluation
des arguments.
Exemples :
(+ (+ 1 2) (* 3 4)) ; renvoie 15(1 + 2) ; erreur : 1 n'est pas une fonction(toto (1 2 3)) ; erreur : 1 n'est pas une fonction((toto 1)) ; erreur : (toto 1) n'est pas une fonction |
3.4.
Formes spéciales
Dans certains cas (nous allons en voir très bientot), on ne souhaite pas que les arguments soient évalués avant l'application d'une fonction. On parle alors de "forme spéciale" plutot que de "fonction".
3.5.
Définition d'une fonction
Pour définir une fonction, on utilise la forme spéciale define.
|
|
(define nom-de-fonction (lambda liste-d'arguments corps-de-la-fonction )) |
- si on n'a pas besoin d'argument, liste-d'arguments est la liste vide : ()
- on peut (doit) insérer des commentaires. Ceux-ci sont indiqués par un point-virgule. Scheme ne lit pas le reste de la ligne.
- pour plus de lisibilité, il faut indenter le programme, c'est-à-dire décaler vers la droite chaque fois qu'on ouvre une parenthèse, et revenir à gauche quand on la ferme
Exemples :
? (define plus-1 (lambda (x) (+ x 1) ))plus-1? (plus-1 5)6? |
Je fournisla définitionde ma fonction Scheme indique qu'il a comprisJe testeScheme affiche le résultatIl est prêt pour la suite |
? (define somme (lambda (x y z) (+ (+ x y) z ) ))somme? (somme 1 2 3)6? |
là j'exagère un peu l'indentation(+ (+ x y) z)serait plus lisible |
Dans les exemples ci-dessus, ? est le prompt. Il signifie que Scheme attend une expression à évaluer. Lorsqu'il évalue un define, il renvoie le nom de la fonction.
3.x.
Matériellement
4-Briques
de base
4.1.
Programme "minimum"
Reprenons l'exemple du 2.4. :
minimum d'une liste si la liste n'a qu'un élément c'est l'élément de la liste sinon si le premier élément de la liste est plus petit que le minimum de la sous-liste obtenue en enlevant le premier élément c'est le premier élément de la liste sinon c'est le minimum de la sous-liste obtenue en enlevant le premier élément finsi finsifinminimum |
En Scheme, cela va s'écrire :
(define minimum (lambda (liste) (if (= (length liste) 1)(car liste) (if (< (car liste) (minimum (cdr liste))) (car liste) (minimum (cdr liste)) ) ) )) |
4.2.
Fonctions et formes utilisées
|
forme ou fonction |
syntaxe |
sémantique |
|
Forme spéciale if |
(if condition si-oui si-non) |
on évalue condition. Si la réponse est "vrai", on évalue si-oui. Si la réponse est "faux", on évalue si-non. |
|
Fonction = |
(= nombre1 nombre2) |
si les deux nombres ont la même valeur, retourne "vrai", sinon retourne "faux". |
|
Fonction length |
(length liste) |
retourne la longueur de la liste liste. Retourne 0 pour une liste vide. |
|
Fonction car |
(car liste) |
retourne le premier élément de liste. |
|
Fonction < |
(< nombre1 nombre2) |
si nombre1 est strictement inférieur à nombre2, retourne "vrai", sinon "faux". |
|
Fonction cdr |
(cdr liste) |
retourne la liste liste privée de son premier élément. |
![]() Si
liste a deux éléments, son cdr est une liste à un élément. Si
liste n'a qu'un élément, son cdr est la liste vide ().
Si
liste a deux éléments, son cdr est une liste à un élément. Si
liste n'a qu'un élément, son cdr est la liste vide ().
4.3.
Notion de "vrai" et de "faux"
|
|
"faux", en Scheme, est représenté par le symbole
spécial #f . "vrai" est tout ce qui n'est pas #f
. Il existe un symbole spécial, #t (comme "true"),
mais il n'est pas nécessaire. |
![]() La
version de Scheme implantée à l'UCB ne respecte pas tout à fait cette règle
: la liste vide est considérée comme "faux".
La
version de Scheme implantée à l'UCB ne respecte pas tout à fait cette règle
: la liste vide est considérée comme "faux".
4.4.
Test du programme
A présent que nous avons écrit le programme "minimum", testons le :
? (minimum (3 6 5.5 12 -2 0 7 89 36))Error : bad procedure 3?
Nous avons déjà oublié le paragraphe 3.3.!
Comment faire pour tester notre programme? Il faut empêcher Scheme d'évaluer
l'argument. Nous introduisons pour cela une nouvelle forme spéciale.
4.5. La
forme spéciale quote
![]() (quote
n'importe quoi)
(quote
n'importe quoi)
![]() retourne
son argument sans l'évaluer.
retourne
son argument sans l'évaluer.
Abréviation : cette forme étant très très souvent utilisée, pour aller plus
vite on peut la remplacer par une apostrophe et supprimer la paire de
parenthèses.
'toto est rigoureusement équivalent à (quote toto)
Nous pouvons à présent tester notre programme :
? (minimum '(3 6 5.5 12 -2 0 7 89 36))-2?
4.6. La
fonction cons
Supposons maintenant que je veuille le minimum de deux listes. Je peux écrire:
(define mini2 (lambda (liste1 liste2) (if (< (minimum liste1) (minimum liste2)) (minimum liste1) (minimum liste2)) ) ) |
Mais c'est maladroit. Il serait plus astucieux de dire : je
vais faire la liste des minima, et lui appliquer la fonction minimum. Comment
construire cette liste? A l'aide de la fonction cons.
![]() (cons
élément liste)
(cons
élément liste)
![]() retourne
la liste dont le car est élément et dont le cdr est liste
retourne
la liste dont le car est élément et dont le cdr est liste
|
|
Le second argument doit être une liste. |
Il faut donc pouvoir transformer un atome en liste.
|
|
|
Pour transformer un atome en liste, il suffit de le conser
avec la liste vide. |
Sachant cela, nous pouvons écrire notre fonction mini2 :
(define mini2 (lambda (liste1 liste2) (minimum (cons (minimum liste1) (cons (minimum liste2) '())) ) ) ) |
5-Mémorisation
5.1.
Problème
Reprenons notre programme "minimum"
(define minimum (lambda (liste) (if (= (length liste) 1)(car liste) (if (< (car liste) (minimum (cdr liste))) (car liste) (minimum (cdr liste))) ) ) ) |
Ce programme est correct, mais maladroit. En effet, la fonction "minimum" est appelée deux fois avec les mêmes arguments (une fois pour savoir si son résultat est intéressant, une fois pour prendre son résultat).
5.2.
Solution
Il serait astucieux de conserver le résultat du premier
appel dans un mot-mémoire, pour s'en resservir, au lieu de provoquer le
deuxième appel. Pour ce faire, on dispose, en Scheme, de la forme spéciale let.
![]()
(let ((ident1 val1)(ident2 val2)
... (identn valn))
corps)
![]() on
évalue les vali (dans un ordre quelqonque) et on les affecte aux
identi ; dans le corps, on peut utiliser les identi.
on
évalue les vali (dans un ordre quelqonque) et on les affecte aux
identi ; dans le corps, on peut utiliser les identi.
![]() Les
évaluations se font dans un ordre quelconque, et ne doivent donc pas supposer
que l'évaluation précédente a déjà été faite.
Les
évaluations se font dans un ordre quelconque, et ne doivent donc pas supposer
que l'évaluation précédente a déjà été faite.
![]() identi
n'est pas défini à l'extérieur du corps (ou, pire, a la définition qu'il avait
avant qu'on ne pénètre dans le let (cas de lets imbriqués))
identi
n'est pas défini à l'extérieur du corps (ou, pire, a la définition qu'il avait
avant qu'on ne pénètre dans le let (cas de lets imbriqués))
![]() Vous
verrez parfois, dans des documents émanant de non-informaticiens, les identi
appelés "variables". C'est une grossière erreur, car ils ne varient
pas. Nous les appellerons identificateurs
Vous
verrez parfois, dans des documents émanant de non-informaticiens, les identi
appelés "variables". C'est une grossière erreur, car ils ne varient
pas. Nous les appellerons identificateurs
5.3.
Réécriture du programme "minimum"
Nous pouvons à présent optimiser notre programme :
(define minimum (lambda (liste) (if (= (length liste) 1)(car liste) (let ((c (car liste)) (m (minimum (cdr liste)))) (if (< c m) c m) ) ) ) ) |
5.4. let*
Du fait que les évaluations des identi se font "en parallèle", si un identificateur dépend d'un autre, on est obligé d'imbriquer les lets, ce qui est lourd. let* fonctionne comme let, sauf que les évaluations se font en séquentiel.
(let* ((a 5) (b (+ a 1)))
...
affecte 6 à b, alors que
(let ((a 5) (b (+ a 1)))
...
provoquera une
erreur, à moins que a soit déjà défini avant qu'on n'entre dans le let.
6-Tris
Considérons une liste de nombres, par exemple (3 6 5.5 12 -2
0 7 89 36)
La question est de trier une telle liste dans l'ordre croissant, pour obtenir,
ici, (-2 0 3 5.5 6 7 12 36 89)
6.1.
Tri par insertion
On suppose la liste de longueur n-1 triée, et on glisse le nombre restant à la bonne place. Sauf quand la longueur de la liste à trier est 1, auquel cas il n'y a rien à faire.
(define tri (lambda (liste) (if (= (length liste) 1)liste (insere (car liste) (tri (cdr liste)))) ) ) |
Comment insérer un élément dans une liste, sachant qu'elle
est triée? Eh bien, si l'élément est plus petit que le car de la liste,
il suffit de le coller devant.
Sinon, On met le car "de côté", et on se repose le problème
avec le cdr.
Sans oublier le cas particulier où la liste est vide.
(define insere (lambda (elem liste)(if (= (length liste) 0 (cons elem '()) (if (< elem (car liste))(cons elem liste) (cons (car liste) (insere elem (cdr liste)))) ) ) ) |
Ouh la la! Ca marche, ça? Déroulons un exemple :
? (insere 12 '(-2 0 7 36 89))1 Enter INSERE 12 (-2 0 7 36 89) 2 Enter INSERE 12 (0 7 36 89) 3 Enter INSERE 12 (7 36 89) 4 Enter INSERE 12 (36 89) 4 Exit INSERE (12 36 89) 3 Exit INSERE (7 12 36 89) 2 Exit INSERE (0 7 12 36 89)1 Exit INSERE (-2 0 7 12 36 89)(-2 0 7 12 36 89) |
Et le tri?
1 Enter TRI (3 6 5.5 12 -2 0 7 89 36) 2 Enter TRI (6 5.5 12 -2 0 7 89 36) 3 Enter TRI (5.5 12 -2 0 7 89 36) 4 Enter TRI (12 -2 0 7 89 36) 5 Enter TRI (-2 0 7 89 36) 6 Enter TRI (0 7 89 36) 7 Enter TRI (7 89 36) 8 Enter TRI (89 36) 9 Enter TRI (36) 9 Exit TRI (36)9 Enter INSERE 89 (36) 10 Enter INSERE 89 NIL 10 Exit INSERE (89) 9 Exit INSERE (36 89) 8 Exit TRI (36 89) 8 Enter INSERE 7 (36 89) 8 Exit INSERE (7 36 89) 7 Exit TRI (7 36 89) 7 Enter INSERE 0 (7 36 89) 7 Exit INSERE (0 7 36 89) 6 Exit TRI (0 7 36 89) 6 Enter INSERE -2 (0 7 36 89) 6 Exit INSERE (-2 0 7 36 89) 5 Exit TRI (-2 0 7 36 89) 5 Enter INSERE 12 (-2 0 7 36 89) 6 Enter INSERE 12 (0 7 36 89) 7 Enter INSERE 12 (7 36 89) 8 Enter INSERE 12 (36 89) 8 Exit INSERE (12 36 89) 7 Exit INSERE (7 12 36 89) 6 Exit INSERE (0 7 12 36 89) 5 Exit INSERE (-2 0 7 12 36 89) 4 Exit TRI (-2 0 7 12 36 89) 4 Enter INSERE 5.5 (-2 0 7 12 36 89) 5 Enter INSERE 5.5 (0 7 12 36 89) 6 Enter INSERE 5.5 (7 12 36 89) 6 Exit INSERE (5.5 7 12 36 89) 5 Exit INSERE (0 5.5 7 12 36 89) 4 Exit INSERE (-2 0 5.5 7 12 36 89) 3 Exit TRI (-2 0 5.5 7 12 36 89) 3 Enter INSERE 6 (-2 0 5.5 7 12 36 89) 4 Enter INSERE 6 (0 5.5 7 12 36 89) 5 Enter INSERE 6 (5.5 7 12 36 89) 6 Enter INSERE 6 (7 12 36 89) 6 Exit INSERE (6 7 12 36 89) 5 Exit INSERE (5.5 6 7 12 36 89) 4 Exit INSERE (0 5.5 6 7 12 36 89) 3 Exit INSERE (-2 0 5.5 6 7 12 36 89) 2 Exit TRI (-2 0 5.5 6 7 12 36 89) 2 Enter INSERE 3 (-2 0 5.5 6 7 12 36 89) 3 Enter INSERE 3 (0 5.5 6 7 12 36 89) 4 Enter INSERE 3 (5.5 6 7 12 36 89) 4 Exit INSERE (3 5.5 6 7 12 36 89) 3 Exit INSERE (0 3 5.5 6 7 12 36 89) 2 Exit INSERE (-2 0 3 5.5 6 7 12 36 89)1 Exit TRI (-2 0 3 5.5 6 7 12 36 89)(-2 0 3 5.5 6 7 12 36 89) |
6.2. La
fonction null?
Pour savoir si une liste est vide, nous avons écrit : (if (=
(length liste) 0)...
C'est correct, mais pas très élégant. Il existe un prédicat pour répondre à
cette question :
![]() (null?
liste)
(null?
liste)
![]() renvoie
#t si la liste est vide, #f sinon.
renvoie
#t si la liste est vide, #f sinon.
6.3.
Tri-fusion
Il y a une autre manière de trier (en fait, il y en a beaucoup
d'autres). Elle consiste à diviser la liste en deux sous-listes de même longueur,
récursivement, puis à recombiner les sous-listes : 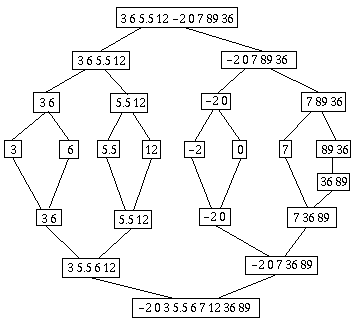
Commençons par la deuxième phase, celle de fusion. Elle se fait en prenant le
plus petit des cars des deux listes, et en collant derrière la fusion
des deux listes restantes.
(define fusion (lambda (liste1 liste2)(if (null? liste1) liste2 (if (null? liste2)liste1 (if (< (car liste1) (car liste2)) (cons (car liste1) (fusion (cdr liste1) liste2)) (cons (car liste2) (fusion liste1 (cdr liste2)))) ) ) ) ) |
Il nous faut également pouvoir
prendre une sous-liste d'une liste, depuis le i-ème élément jusqu'au j-ème.
En Scheme, le n-ème élément d'une liste est donné par la fonction list-ref.
![]() (list-ref
liste rang)
(list-ref
liste rang)
![]() retourne
le (rang-1)ème élément de liste.
retourne
le (rang-1)ème élément de liste.
![]() Le
premier (en français) est le zéroème en Scheme.
Le
premier (en français) est le zéroème en Scheme.
(define sous-liste (lambda (liste i j)(if (= i j) '() (cons (list-ref liste i) (sous-liste (cdr liste) i (- j 1)))) ) ) |
Nous pouvons à présent écrire notre algorithme de tri.
(define tri-fusion (lambda (liste)(if (= (length liste) 1) liste (let* ((long (length liste))(demi (quotient long 2)) ; quotient renvoie un entier, alors ; que / renvoie le résultat exact (liste1 (sous-liste liste 0 demi)) (liste2 (sous-liste liste demi long)) ) (fusion (tri-fusion liste1) (tri-fusion liste2))) ) ) ) |
6.4.
Complexité
Considérons une
liste de longueur n, triée par l'algorithme tri-fusion.
Pour descendre, l'algorithme s'appelle 2 fois, puis 4 fois, puis 8 fois, puis 24
fois, puis 25 fois... et enfin 2p fois pour aboutir à n
feuilles.
On a (à peu près) 2p = n, donc p = log2n.
On appelle donc l'algorithme 21 + 22 + ... + 2p
fois, c'est-à-dire 2p+1 = 2n fois.
Dans la deuxième moitié, on appelle l'algorithme "fusion" autant de
fois.
Au passage, dans "fusion", on appelle 2 fois "sous-liste",
sur des listes de longueur variant entre 1 et n. Et
"sous-liste" s'appelle récursivement.
Ca fait combien d'opérations, tout ça? Est-ce que ça en fait plus que pour
l'algorithme de tri par insertion? Est-ce que ça en fait nettement moins si la
liste est déjà presque triée?
Nous ne répondrons pas ici à ces questions de complexité, qui feront l'objet d'un
autre cours.
7-Modèles
de données
7.1
Problème
Supposons que je veuille faire du calcul matriciel. J'ai besoin, par exemple, de travailler avec la matrice
1 2 3 45 6 7 89 10 11 12
La mémoire est linéaire, donc je vais représenter cette matrice, soit par la liste
(1 2 3 4 5 6 7 8 9 10 11 12)
soit par la liste
(1 5 9 2 6 10 3 7 11 4 8 12)
![]() Supposons
que je choisisse la deuxième représentation. Si je veux l'élément de la i-ème
ligne et de la j-ème colonne, ce sera le ((j-1)*3 + i) ème élément de la liste.
Supposons
que je choisisse la deuxième représentation. Si je veux l'élément de la i-ème
ligne et de la j-ème colonne, ce sera le ((j-1)*3 + i) ème élément de la liste.
Donc je récupérerai l'élément de la i-ème ligne et de la j-ème colonne par
(list-ref matr (+ (* (- j 1) 3) (- i 1)))
Pour une matrice de 5 lignes au lieu de 3, ce sera
(list-ref matr (+ (* (- j 1) 5) (- i 1)))
- c'est long à écrire, surtout si j'ai besoin de l'écrire plusieurs fois
- si je change les dimensions de ma matrice, il faut passer en revue tout le programme pour modifier partout où de telles expressions apparaissent
- si je reprends le programme dans un an, je vais passer longtemps à comprendre pourquoi j'ai écrit ça
7.2
Solution
|
|
Lorsque j'écris (list-ref matr (+ (* (- j 1) 3) (- i
1))), je fais appel à une connaissance implicite : si je
vous ai expliqué, vous comprenez (jusqu'à ce que vous oubliiez), si je n'ai
pas expliqué il vous sera très difficile de comprendre que cela renvoie le
terme de la i-ème ligne et de la j-ème colonne d'une matrice à trois lignes. |
(define get-elem-matrice3; recupere un element d'une matrice ayant trois lignes et un nombre; quelconque de colonnes (lambda (matrice ligne colonne) (list-ref matrice (+ (* (- colonne 1) 3) ; pour un nombre quelconque de; lignes, changer ici (- ligne 1) ) ) )) |
Et je vais ainsi
définir autant de fonctions qu'il y a d'opérations à faire sur cette matrice,
si élémentaires soient-elles. Ainsi, je n'ai plus à me soucier de la manière
dont cette matrice est représentée.
Si un jour je trouve une représentation plus astucieuse, il me suffira de
modifier quelques fonctions, je n'aurai rien à changer à mon programme, parce
que mon programme travaille sur la notion abstraite de matrice, et non pas sur
la représentation en machine de cette notion.
De même (cf. 1.4), je n'ai pas besoin de savoir que le caractère "1"
est représenté par le nombre 49 en ASCII, ni que ce nombre est représenté par
110001 en binaire. Il faut que mes programmes continuent à fonctionner même si
ces représentations changent (cf. bug de l'an 2000).
8-Le
modèle de données "arbre"
Reprenons la structure d'un répertoire :
Les répertoires et fichiers sont structurés sous forme d'un arbre.
8.1.
Définitions
Comme les arbres de la nature, un arbre informatique a une
(et une seule) racine, des branches, des noeuds, et des feuilles ; la seule
différence est que la racine est en haut et les feuilles en bas.
Comme dans un arbre généalogique, on trouve des pères, des fils, des cousins,
etc. La particularité d'un arbre, par rapport à d'autres graphes, est que
chaque noeud a un père (et un seul), sauf la racine, qui n'a pas de père.
8.2.
Représentations
Dans la représentation ci-dessus, les branches de l'arbre représentent le lien entre un noeud et son premier fils, son deuxième fils, etc. Or
|
|
Chaque fois qu'on est obligé de dire "etc." pour décrire quelque chose, on va avoir un problème pour écrire l'algorithme. |
Heureusement, il existe un théorème de théorie des graphes, qui indique que
l'on peut toujours remplacer la représentation "premier fils, deuxième
fils, etc." par la représentation "premier fils, premier frère".
|
|
|
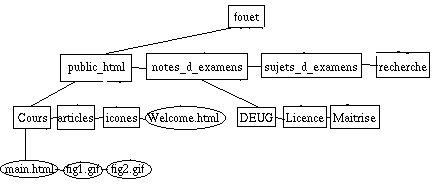
Représenter cela en machine est quasi-évident : on écrit la liste des fils de chaque noeud, liste dont le car donne le premier fils, et dont le cdr donne le reste des fils :
|
|
(fouet (public_html (Cours(main.html fig1.gif fig2.gif) ) articles icones Welcome.html ) (notes_d_examens DEUG Licence Maitrise ) sujets_d_examens recherche) |
8.3.
Représentation arborescente des programmes
Le passage de la notion d'arbre à sa représentation par liste admet une réciproque : une liste peut être représentée par un arbre. Reprenons par exemple le programme :
(define minimum (lambda (liste) (if (= (length liste) 1)(car liste)
(let ((c (car liste)) (m (minimum (cdr liste))))
(if (< c m)c
m ) ) ) ))
Il lui correspond la figure :
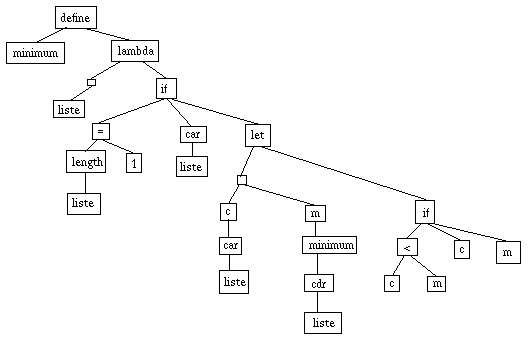
On remarquera l'introduction de noeuds vides, pour les formes spéciales
acceptant un nombre quelconque d'arguments.
8.4.
Parcours d'arbre
Un problème qui va
souvent se poser, c'est de décrire entièrement un arbre, c'est-à-dire
d'énumérer tous ses noeuds, une fois et une seule.
Il existe deux techniques, appelées respectivement "en largeur d'abord"
et "en profondeur d'abord". En "largeur d'abord", on descend
le moins possible 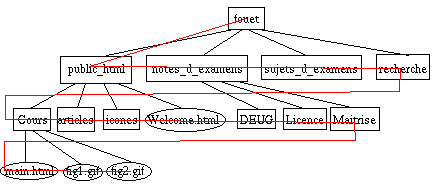
Ce qui nous donne : fouet public_html notes_d_examens sujets_d_examens recherche Cours articles
icones Welcome.html DEUG Licence Maitrise main.html fig1.gif fig2.gif. En "profondeur d'abord",
on descend le plus possible 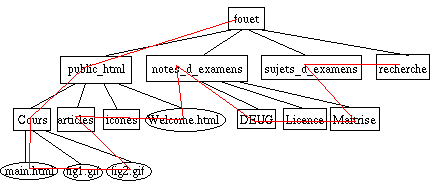
ce qui donne : fouet
public_html Cours main.html fig1.gif fig2.gif articles icones Welcome.html
notes_d_examens DEUG Licence Maitrise sujets_d_examens recherche, c'est-à-dire, aux
parenthèses près, la liste du 8.2.
9-Le
modèle de données "liste"
Eh oui! Déjà huit chapitres que nous parlons de listes, et nous ne savons toujours pas ce que c'est!
9.1.
Définition
En représentation externe, une liste est formée de :
- une parenthèse ouvrante
- un premier truc (le car, qui peut lui-même être une liste)
- un blanc
- un deuxième truc
- un blanc
- etc.
- une parenthèse fermante
La liste vide ne contient aucun "truc" : ()
Une liste réduite à un élément n'a pas besoin de blanc (mais on a le droit d'en
mettre).
En représentation interne, une liste est un arbre binaire,
c'est-à-dire que chaque noeud a exactement deux fils... son car et son cdr
. Par exemple, la liste (a b (c d) e) aura la structure suivante :
|
|
|
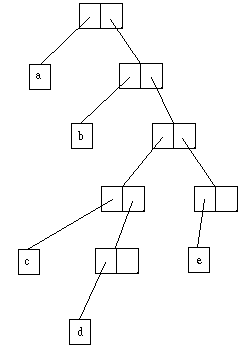
Chaque carré représente un mot-mémoire. Quand ils sont groupés par paires, le carré de gauche pointe sur le car, et celui de droite sur le cdr. S'il ne pointe sur rien, il représente la liste vide.
|
|
Toute (sous-)liste se termine toujours par la liste vide. |
9.2.
Construction d'une liste
Le moyen le plus courant de construire une liste consiste à
utiliser la fonction cons .
![]() (cons
truc liste)
(cons
truc liste)
![]() retourne
une liste, dont le car est truc et dont le cdr est liste.
retourne
une liste, dont le car est truc et dont le cdr est liste.
Exemple : (cons 1 '(2)) renvoie (1 2)
![]() Le
deuxième argument de l'appel à cons est impérativement une liste. Sinon,
cons fonctionne quand même, mais ce qu'il retourne n'est pas une liste,
et ne nous intéresse pas, pour l'instant.
Le
deuxième argument de l'appel à cons est impérativement une liste. Sinon,
cons fonctionne quand même, mais ce qu'il retourne n'est pas une liste,
et ne nous intéresse pas, pour l'instant.
Pour former une liste d'un élément, il faut donc le conser avec la liste vide.
Le second moyen de fabriquer une liste consiste à utiliser la fonction append
.
![]() (append
liste1 liste2)
(append
liste1 liste2)
![]() retourne
la liste formée en collant les éléments de liste2 derrière ceux de
liste1 .
retourne
la liste formée en collant les éléments de liste2 derrière ceux de
liste1 .
Exemple : (append '(a b) '(cd)) retourne '(a b c d) , alors que (cons '(a b)
'(cd)) retourne ((a b) c d)
|
|
|
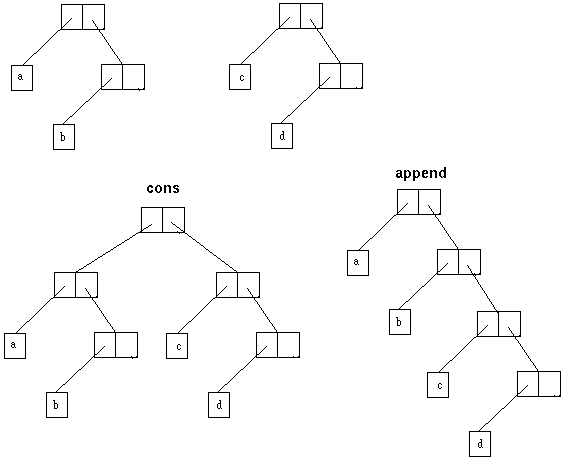
9.3.
Exemple
Ecrivons la fonction aplat qui parcourt un arbre en profondeur d'abord. Si l'arbre n'a qu'un atome, on retourne la liste formée de cet atome. Si c'est une liste formée d'un seul élément, qui peut être une liste, on applique récursivement la fonction à cet élément. Dans le cas général, on applique la fonction au car et au cdr, et on concatène les résultats.
|
|
(define aplat (lambda (a) (if (list? a) (if (= (length a) 1) (aplat (car a)) (append (aplat (car a)) (aplat (cdr a))) ) (cons a '()) ) ) ) |
Remarque : cet
exemple est un peu mal choisi, car il donne autant d'importance à append
qu'à cons . En pratique, vous utiliserez beaucoup plus souvent le second
que le premier.
Nous avons introduit la fonction list? :
 (list
truc)
(list
truc)
 retourne
#t si truc est une liste, #f sinon.
retourne
#t si truc est une liste, #f sinon.
10- Le
modèle de données "pile"
10.1.
Problème
Reprenons le programme "minimum"
(define minimum (lambda (liste) (if (= (length liste) 1)(car liste) (let ((c (car liste)) (m (minimum (cdr liste)))) (if (< c m)c m) ) ) ) ) |
et exécutons le, par exemple sur la liste (1 3 2).
- (1 3 2) a-t-elle pour longueur 1? non
- soit c = 1
- soit m = (minimum '(3 2))
- (3 2) a-t-elle pour longueur 1? non
- soit c = 3
- soit m (minimum '(2))
- (2) a-t-elle pour longueur 1? oui
- je renvoie 2 dans m
- c, c'est-à-dire 3, est-il inférieur à 2? non
- je renvoie 2 dans m
- c, c'est-à-dire 3, est-il inférieur à 2? non
et je suis complètement perdu. Parce que j'ai écrasé c=1 par c=3.
10.2.
Solution
Il aurait fallu, au lieu d'écraser c=1 par c=3, créer un
nouveau c pour y ranger 3, sans perdre le c qui valait 1. Quand je reviens de
l'appel à la fonction "minimum", lequel des "c" dois-je
prendre? Le plus récent.
C'est donc exactement comme les papiers empilés sur mon bureau : quand je
décide de les examiner, je commence par celui qui est au sommet de la pile,
donc qui est arrivé en dernier.
- (1 3 2) a-t-elle pour longueur 1? non
- empiler 1
- soit m = (minimum '(3 2))
- (3 2) a-t-elle pour longueur 1? non
- empiler 3
- soit m (minimum '(2))
- (2) a-t-elle pour longueur 1? oui
- je renvoie 2 dans m
- dépiler, donne c =3
- 3 est-il inférieur à 2? non
- je renvoie 2 dans m
- dépiler, donne c = 1
- 1 est-il inférieur à 2? oui
- je renvoie 1
- dépiler, ah non, erreur, la pile est vide
10.3.
Fonctions liées à la notion de pile
Nous avons donc besoin de quatre fonctions :
- empiler, qui s'appelle traditionnellement "push"
- dépiler, ou "pop"
- savoir si la pile est vide
- et, ce qu'il ne faut jamais oublier, (ré-)initialiser la pile
10.4.
Implémentation : notion de variable
Pour réaliser une pile en machine, il va nous falloir le
moyen de stocker son contenu, ce qui n'est pas difficile, mais aussi de
modifier ce contenu, et cela, pour l'instant, nous ne savions pas le faire. On
introduit donc la notion de variable.
On crée une variable par la forme spéciale define
![]() (define
nom-de-variable valeur)
(define
nom-de-variable valeur)
![]() on
évalue valeur, et on affecte le résultat à nom-de-variable
on
évalue valeur, et on affecte le résultat à nom-de-variable
![]() Il
ne faut pas utiliser define dans un programme.
Il
ne faut pas utiliser define dans un programme.
Pour modifier le contenu d'une variable, on utilise la forme spéciale set!
![]() (set!
nom-de-variable valeur)
(set!
nom-de-variable valeur)
![]() on
évalue valeur, et on affecte le résultat à nom-de-variable
on
évalue valeur, et on affecte le résultat à nom-de-variable
![]() Il
ne faut pas utiliser set! sur un nom qui n'a pas au préalable été défini
par define .
Il
ne faut pas utiliser set! sur un nom qui n'a pas au préalable été défini
par define .
Nous pouvons à présent mettre en place notre pile, sous forme d'une liste :
(define ma-pile '()) |
(define init-pile (lambda () (set! ma-pile '())) ) |
(define pile-vide? (lambda () (null? ma-pile)) ) |
(define push (lambda (truc)(set! ma-pile (cons truc ma-pile)) ) ) |
(define pop (lambda () (if (pile-vide?) (write "Erreur : on essaie de dépiler ma-pile, qui est vide")(let ((top (car ma-pile))) (set! ma-pile (cdr ma-pile)) top) ) ) ) |
On remarquera
qu'on aurait pu se dispenser d'écrire la fonction pile-vide?. Mais c'est
une bonne pratique, typique des modèles de données : on sait ce que fait cette
fonction, et on n'a pas besoin de savoir comment s'appelle la pile ni comment
elle est représentée (par exemple, elle pourrait être représentée autrement que
par une liste).
11-Jeux
11.1.
Principe
Nous ne considérons ici que les jeux dans lesquels toute
l'information est "sur la table" : échecs, go, dames, morpion,
reversi, etc., mais pas bridge ou poker. Il est en général assez facile de
coder les règles du jeu, ce n'est pas notre propos.
Supposons que la partie soit déjà entamée, nous sommes dans l'état S0.
Supposons que ce soit à moi de jouer : les règles du jeu me donnent la liste
des coups possibles (qu'ils soient intéressants ou non n'est pas, pour
l'instant, mon problème). Si je joue, disons, le fou en H4, cela nous amènera
dans l'état S1,1, si par contre je joue la tour en G2 dans l'état S1,2,
etc., jusqu'à l'état S1,n1, avec la seule restriction que le nombre n1
soit fini.
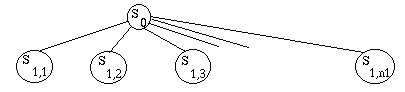
Maintenant, c'est à mon adversaire de jouer. Si j'ai joué le fou en H4, il
peut jouer la reine en I4, nous amenant dans l'état S2,1, ou...
Si j'ai joué la tour, il peut jouer... etc. 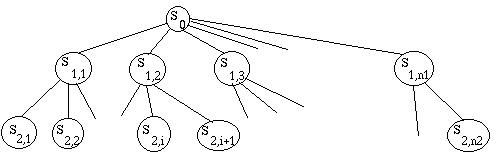
Et ainsi de suite. Il va falloir nous arrêter, au niveau n, car la
complexité est exponentielle. 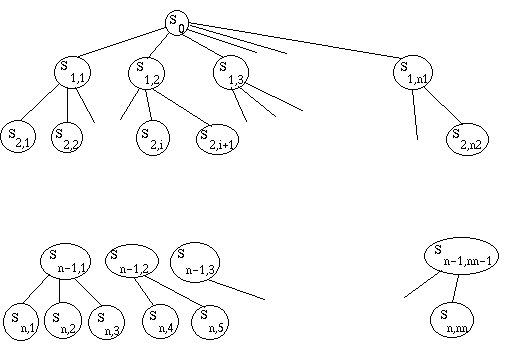
A présent, nous passons en revue chacune des feuilles de l'arbre, qui représente
un état possible au bout de n coups. Sur chacune des feuilles, nous
calculons une fonction d'évaluation, qui donne une note à cet
état, d'autant meilleure que je trouve cet état favorable. Par exemple, je
compte positivement le nombre de pièces que j'ai prises à l'adversaire, négativement
le nombre de pièces que j'ai perdues, négativement le fait qu'une de mes pièces
soit clouée, etc. 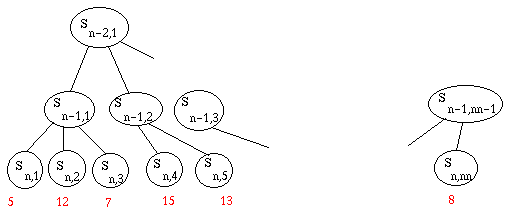
En général, on écrit la fonction d'évaluation sous forme d'un polynome 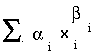 ,
où les "x" sont des caractéristiques de l'état, et les "alpha"
et les "beta" des coefficients qu'on ajustera jusqu'à ce que le
programme joue bien.
,
où les "x" sont des caractéristiques de l'état, et les "alpha"
et les "beta" des coefficients qu'on ajustera jusqu'à ce que le
programme joue bien.
Supposons que c'était à moi de jouer le dernier coup. Dans l'état Sn-1,1,
je choisirais ce qui me rapporte le plus, c'est-à-dire le deuxième. Donc l'état
Sn-1,1 vaut 12. De même, l'état Sn-1,2 vaut le maximum
de ses fils, soit 15. 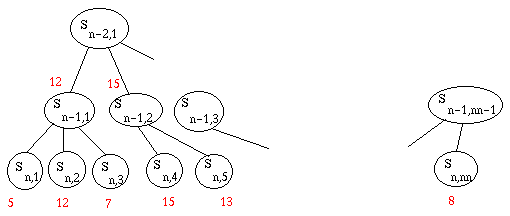
Au niveau n-2, c'est à l'adversaire de jouer. Il choisira évidemment ce qui
me rapporte le moins. Donc Sn-2,1 vaut 12. 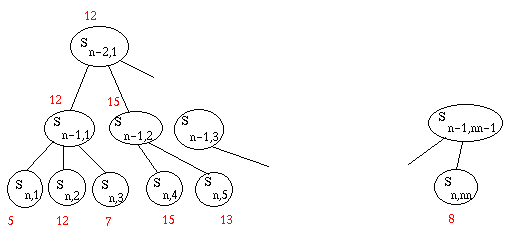
Et ainsi de suite : on remonte alternativement le max et le min des fils. Cet
algorithme s'appelle minimax.
11.2.
Amélioration
La complexité de l'algorithme minimax est pn,
où p est le nombre moyen de coups possibles dans chaque état. C'est
énorme. Il y a un moyen puissant de faire des économies : on développe l'arbre
en profondeur d'abord, et on calcule la fonction d'évaluation chaque fois
qu'on arrive à une feuille. 
Au bout de n+4 calculs (sur notre exemple), l'arbre est comme ceci:
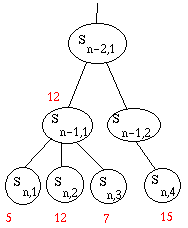
On tient alors le raisonnement suivant : quelles que soient les notes des
autres états fils de Sn-1,2, on remontera au moins 15. Or 15 est
supérieur à 12. Donc l'adversaire ne jouera certainement pas Sn-1,2.
Donc il est inutile de développer ses autres fils! On passe directement au
troisième fils de Sn-2,1. Le raisonnement s'étend évidemment
récursivement : tel noeud au niveau n-2 vaut déjà moins que la valeur actuelle
de Sn-2,1, donc je ne le jouerai évidemment pas, donc inutile de
développer ses autres fils.
L'algorithme ainsi amélioré s'appelle alpha-beta. Il est toujours
de complexité exponentielle, mais "moins".
11.3.
Notion d'heuristique
Il y a des coups que la règle du jeu autorise, mais qu'un bon joueur n'envisagerait même pas, tellement ils sont stupides. Sous réserve de savoir coder cette information, on peut l'utiliser pour :
- ordonner les essais, dans l'algorithme ci-dessus (version "faible" de la notion d'heuristique)
- ne pas faire tous les essais (version "forte")
Noter que, dans la version forte, on n'est plus sur d'obtenir la meilleure solution. Par exemple, une assez bonne heuristique consiste à ne pas perdre de pièces. Mais il existe des cas, nommés "sacrifices", où la perte volontaire d'une pièce mêne à la victoire.
11.4.
Effet d'horizon
A cause de sa complexité exponentielle, l'algorithme minimax
alpha-beta doit être limité à une profondeur n relativement faible. La
fonction d'évaluation doit, pour la même raison, être assez fruste. Donc, s'il
y a un coup "génial" à faire au niveau n+1, en ayant soigneusement
préparé le terrain, on n'a aucun moyen de le voir. C'est ce qu'on appelle
l'effet d'horizon.
12-Codage
Supposons que nous voulions coder cette phrase.
12.1.
ASCII
Le moyen le plus simple est le code ASCII :
|
symbole |
code |
binaire |
|
S |
83 |
01010011 |
|
u |
117 |
01110101 |
|
p |
112 |
01110000 |
|
o |
111 |
01101111 |
|
s |
115 |
01110011 |
|
... |
... |
... |
|
. |
46 |
00101110 |
Puisqu'on sait que chaque caractère est codé sur 8 bits, on
n'a pas besoin de séparateur ; le message est :
01010011011101010111000001110000 ... 00101110 . Il occupe 47*8=376 bits.
12.2.
Codage fixe
On peut arriver à un codage plus économique, en remarquant que les seuls caractères utilisés sont S, u, p, o, s, n, blanc, q, e, v, l, i, c, d, r, t, h, a, et point, soit 19 caractères.
|
symbole |
code |
binaire |
|
S |
0 |
00000 |
|
u |
1 |
00001 |
|
p |
2 |
00010 |
|
o |
3 |
00011 |
|
s |
4 |
00100 |
|
... |
... |
... |
|
. |
18 |
10010 |
Le message devient :
0000000001000100001000011 ... 10010 , et n'occupe plus que 47*5 = 235 bits.
12.3.
Codage optimal
Etudions les fréquences des caractères employés :
|
symbole |
fréquence |
|
S |
1 |
|
u |
4 |
|
p |
3 |
|
o |
6 |
|
s |
5 |
|
n |
3 |
|
blanc |
6 |
|
q |
1 |
|
e |
5 |
|
v |
1 |
|
l |
1 |
|
i |
1 |
|
c |
2 |
|
d |
1 |
|
r |
2 |
|
t |
2 |
|
h |
1 |
|
a |
1 |
|
. |
1 |
Ordonnons les par fréquence décroissante, et numérotons les :
|
symbole |
fréquence |
numéro |
binaire |
|
o |
6 |
0 |
0 |
|
blanc |
6 |
1 |
1 |
|
s |
5 |
2 |
10 |
|
e |
5 |
3 |
11 |
|
u |
4 |
4 |
100 |
|
p |
3 |
5 |
101 |
|
n |
3 |
6 |
110 |
|
c |
2 |
7 |
111 |
|
r |
2 |
8 |
1000 |
|
t |
2 |
9 |
1001 |
|
S |
1 |
10 |
1010 |
|
q |
1 |
11 |
1011 |
|
v |
1 |
12 |
1100 |
|
l |
1 |
13 |
1101 |
|
i |
1 |
14 |
1110 |
|
d |
1 |
15 |
1111 |
|
h |
1 |
16 |
10000 |
|
a |
1 |
17 |
10001 |
|
. |
1 |
18 |
10010 |
Nous pouvons alors coder le message par :
101010010110101001101011011100 ... 10010( S)(u)(p)(p)o so(n) sb( q)(u) ... ( . )
Il n'occupe plus que : (6*1) + (6*1) + (5*2) + (5*2) + (4*3)
+ (3*3) + (3*3) + (2*3) + (2*4) + (2*4) + 6*4 + 3*5 = 123 bits.
Mais nous ne pouvons plus le décoder !
Il nous faudrait un séparateur. Ce ne peut être qu'une chaine de bits que l'on
est sûr de ne pas confondre avec un caractère, ni avec une succession de
caractères. Par exemple, 10011 n'est pas un caractère, mais pourrait très bien
être "ue", ou "blanc o o blanc blanc".
12.4.
Huffman
12.4.1.
Principe
La solution consiste à ce qu'aucun code ne soit préfixe
d'un autre.
Nous pouvons garder "0" pour "o", puisqu'aucun autre code
ne commence par "0".
En revanche, nous ne pouvons pas garder "1" pour "blanc".
Mais nous pouvons prendre "10", à condition de nous interdire qu'un
autre code commence par "10".
Il est clair que nous ne pouvons pas prendre "11" pour "s",
à moins de nous interdire des codes commençant par "11", ce qui est
impossible puisque nous avons déjà interdit "10xxx".
12.4.2.
Arbre binaire
Formalisons le raisonnement intuitif précédent.
J'ai 47 occurrences à répartir, et il est clair qu'il faut que les caractères
les plus fréquents aient le code le plus court.
J'affecte donc "0" aux 6 "o", il me reste 41 occurrences à
affecter.
Si j'affecte "10" à "blanc", et "11..." au reste,
je suis parti pour développer une liste plate :
Je vais bientot dépasser les 8 bits!
Si, au contraire, je fais un arbre binaire "symetrique", c'est-à-dire
avec autant de "0" que de "1" :
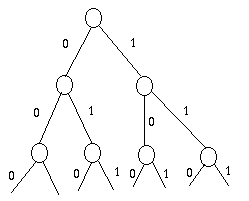
Je vais aboutir... à un code de longueur fixe (la longueur sera le log du
nombre de caractères). J'ai gâché la fréquence.
La solution est donc intermédiaire entre la liste "plate" et l'arbre
"symétrique". Plus je descends, plus je laisse les sous-arbres de
gauche se développer :
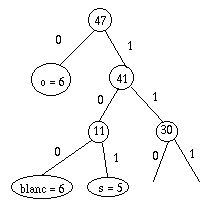
C'est-à-dire que je code
- Sur 1 bit le caractère le plus fréquent
- Sur 3 bits les deux plus fréquents restant
- Sur 5 bits les 4 plus fréquents restant
- Sur 2n+1 bits les 2n plus fréquents restant
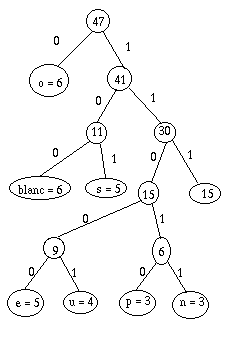
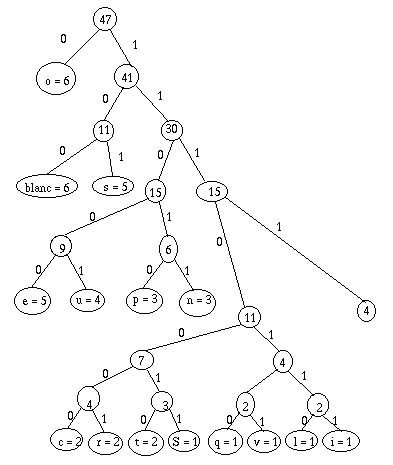
- Avec le cas particulier final où, s'il n'en reste pas 2n, je peux me contenter de 2n bits.
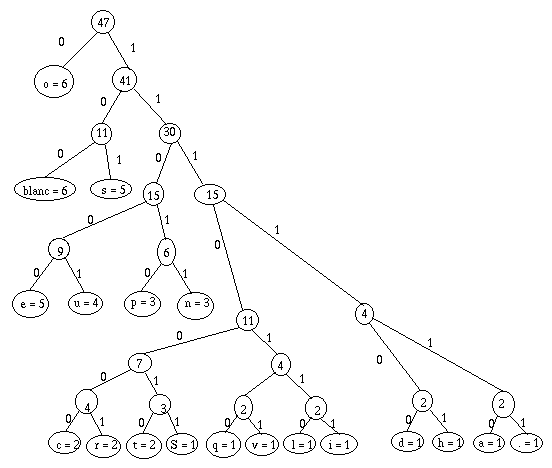
12.4.3.
Bilan
Mon message devient :
1110011110011101011010010101101 ... 111111( S )( u )( p )( p )o(s)o( n) ... ( . )
Il occupe (6*1) + (6*3) + (5*3) + (5*5) + (4*5) + (3*5) +
(3*5) + (3*(2*7)) + (5*(1*7)) + (4*(1*6)) = 213 bits.
C'est plus que le codage précédent, mais, cette fois-ci, je peux le décoder :
- Je pars de la racine
- si je trouve un "0", je vais au fils gauche
- sinon, je vais au fils droit
- quand il n'y a plus de fils (feuille), j'ai mon caractère
- Je repars de la racine
Ce codage est-il optimal? Non : j'aurais mieux fait de coder "c", "r" et "t" sur 6 bits.
12.4.4.
Idée de l'algorithme
Si vous regardez les figures ci-dessus, votre tendance
naturelle consiste à lire les arbres de haut en bas. D'ailleurs, j'ai construit
les arbres successifs en commençant par la racine, puis en développant vers le
bas.
Mais, si vous essayez de comprendre les nombres qui sont dans les cercles, vous
êtes obligé(e) de lire les arbres de bas en haut, puisque ces nombres sont les
sommes des occurrences des noeuds inférieurs.
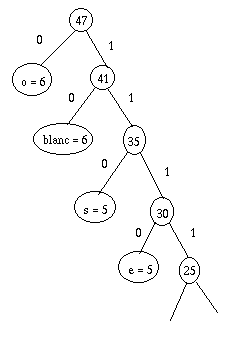
L'algorithme de Huffman part du bas, c'est-à-dire qu'il va regrouper des
feuilles en petits arbres, puis fusionner ces petits arbres pour en donner de
plus gros, et ainsi de suite. Donc on va commencer par les caractères les moins
fréquents, de manière à ce qu'ils restent le plus bas possible, afin de garder
les codes les plus courts pour les caractères les plus fréquents.
Reprenons notre tableau :
|
symbole |
fréquence |
|
o |
6 |
|
blanc |
6 |
|
s |
5 |
|
e |
5 |
|
u |
4 |
|
p |
3 |
|
n |
3 |
|
c |
2 |
|
r |
2 |
|
t |
2 |
|
S |
1 |
|
q |
1 |
|
v |
1 |
|
l |
1 |
|
i |
1 |
|
d |
1 |
|
h |
1 |
|
a |
1 |
|
. |
1 |
Je regroupe le "point" et le "a":
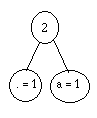
et les autres petits, deux par deux :
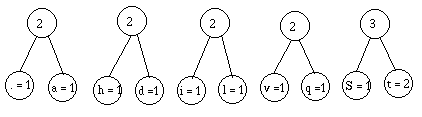
Je trie :

Je regroupe deux par deux :
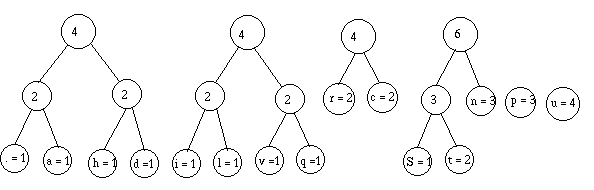
Stop! Je retrie :
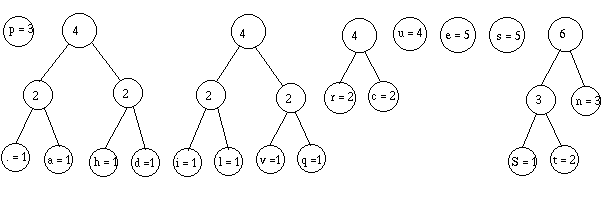
Je regroupe :
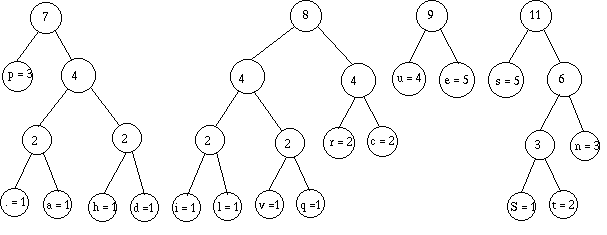
Je retrie :
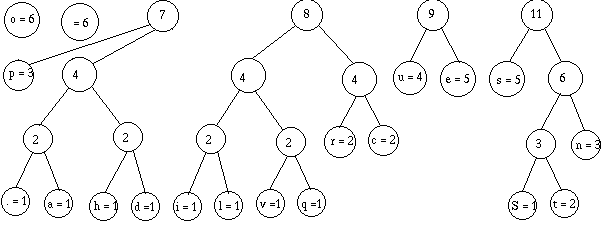
Je regroupe :
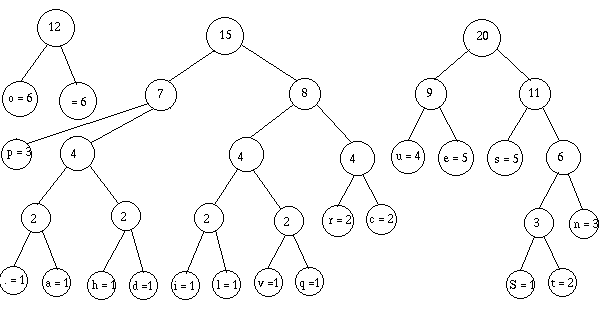
Eventuellement, je retrierais, mais il se trouve que je n'en ai pas besoin,
alors je regroupe :
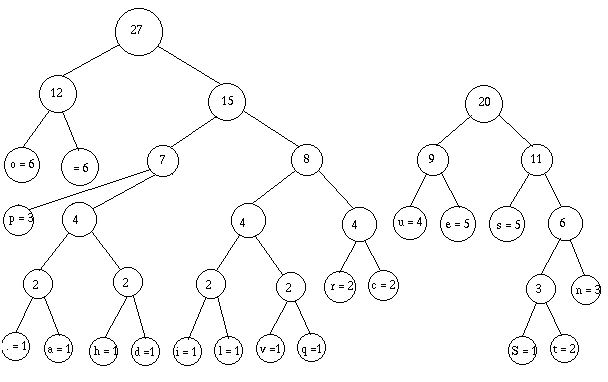
Je retrie, et j'ai fini :
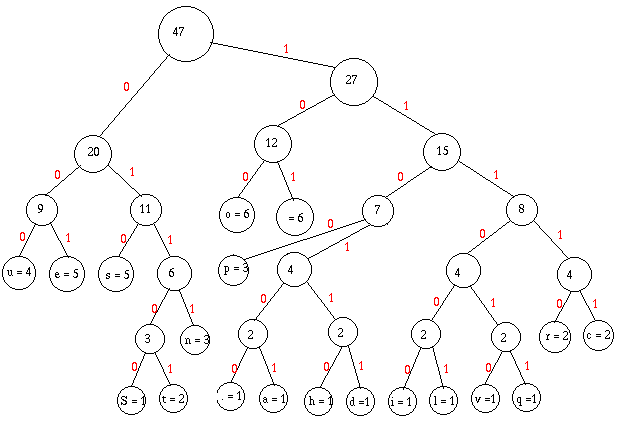
Soit, faîtes le calcul : 185 bits. Qui dit mieux?
Personne : on démontre que le codage obtenu est optimal (sauf cas très
particuliers de déséquilibre énorme entre les fréquences, auquel cas on peut
faire encore mieux, mais au prix d'une forte augmentation du temps de calcul).
12.4.5.
Algorithme d'encodage
- lire le texte à coder
Exemple : '("S" "u" "p" "p" "o" "s" "o" "n" "s" " " "q" "u" ... ".") - calculer la fréquence de chaque caractère dans le texte
- Mais une fonction ne renvoie qu'un résultat !?!
- Oui, mais rien n'empèche ce résultat d'être :
- une liste de couples ((carac1 freq1) (carac2 freq2) ... (caracn freqn))
- ou une liste de listes ((carac1 ... caracn) (freq1 ... freqn))
- ou même ((carac1 ... caracn) freq1 ... freqn), dont le cdr est la deuxième liste voulue
Exemple : (("S" 1)
("u" 4) ("p" 3) ... ("." 1))
- trier la liste de couples
(carac freq) suivant les fréquences croissantes
Exemple : (("S" 1) ("q" 1) ("v" 1) ... ("o" 6)) - construire l'arbre
Exemple : (47 (20 (9 ("u" 4) ("e" 5)) (11 ("s" 5) (" " 6))) (27 (12 .... ("c" 2)))))
Cela demande de savoir : - Fusionner deux
feuilles
Exemple : ("S" 1) et ("q" 1) -> (2 ("S" 1) ("q" 1)) - Fusionner deux
arbres
Exemple : (2 ("S" 1) ("q" 1)) et (2 ("v" 1) ("l" 1)) -> (4 (2 ("S" 1) ("q" 1)) (2 ("v" 1) ("l" 1))) - ou fusionner un
arbre et une feuille
Toutes ces opérations peuvent être réalisées par la même fonction, du moment que la fonction qui calcule le poids de chaque morceau sait faire la différence entre un arbre et une feuille. - Mettre l'arbre obtenu à la bonne place dans la liste, ce qui n'est pas difficile si la fonction de tri écrite précedemment utilise un tri par insertion.
- construire la table de
codage
Exemple : (("u" (0 0 0)) ("e" (0 0 1)) ... ("c" (1 1 1 1 1)))
En partant de la racine, on met (0) quand on prend le fils gauche, (1) quand on prend le fils droit, et on "appende" jusqu'à ce qu'on trouve les feuilles. - coder
Exemple : (0110000011001100100 ... 110100)
12.4.6.
Algorithme de décodage
Etant donné une liste telle que celle ci-dessus, on peut,
bien entendu, la décoder à l'aide de la table, mais la procédure est assez
lourde. Il est beaucoup plus simple de repartir de l'arbre.
Cependant, la procédure est un petit peu délicate, dans la mesure où :
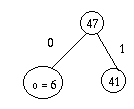
- je cherche quel caractère correspond aux premiers bits, donc je parcours l'arbre
- mais, quand j'aurai trouvé, il faudra recommencer pour les bits suivants, donc reprendre l'arbre à la racine.
Cela explique pourquoi on passe deux fois l'arbre à la fonction : une fois pour qu'elle le parcoure, une fois pour qu'elle le conserve pour l'avenir.
- (0110000011001100100 ... 110100) 47 47 : le car est un 0, je vais à gauche
- (110000011001100100 ... 110100) 20 47 : le car est un 1, je vais à droite
- (10000011001100100 ... 110100) 11 47 : le car est un 1, je vais à droite
- (0000011001100100 ... 110100) 6 47 : le car est un 0, je vais à gauche
- (000011001100100 ... 110100) 3 47 : le car est un 0, je vais à gauche
- C'est une feuille, je stocke "S", et je repars avec :
- (00011001100100 ... 110100) 47 47
13-Scheme
: quelques petits trucs
13.1. list
Ne seriez-vous pas un peu las(se) d'écrire (cons truc
'()) ?
Utilisez la fonction list :
![]() (list
arg1 arg2 ... argn)
(list
arg1 arg2 ... argn)
![]() renvoie
la liste formée des résultats des évaluations de ses arguments.
renvoie
la liste formée des résultats des évaluations de ses arguments.
Exemples :
? (list 5)(5)? (list 'a '(1 2) 12)(a (1 2) 12) |
13.2. cond
Si ... alors ..., sinon, si ... alors ..., sinon, si ...
Les if imbriqués peuvent devenir pénibles. La forme spéciale cond
permet de les regrouper :
![]()
(cond (c1 a1) (c2 a2) ... (cn an)) |
![]() Si
c1 est vraie, on évalue a1, sinon si c2 est vraie, on
évalue a2, sinon ...
Si
c1 est vraie, on évalue a1, sinon si c2 est vraie, on
évalue a2, sinon ...
Si aucune ci n'est vraie, le résultat est imprédictible. D'où
la bonne habitude de mettre toujours en dernier une condition certainement
vraie :
(cond (c1 a1)(c2 a2) ... (#t an)) |
Pour plus de clarté, on préfèrera écrire (mais cela revient rigoureusement au même) :
(cond (c1 a1) (c2 a2) ... (else an)) |
Exemple :
(cond ((>= note 18) "Très bien avec félicitations du jury") ((>= note 16) "Très bien") ((>= note 14) "Bien") ((>= note 12) "Assez bien")((>= note 10) "Passable") (else "Same player shoots again")) |
13.3.
Entrées/sorties
Supposons que vous écriviez une fonction qui, étant donné un prix hors taxes, vous restitue le prix TTC :
? (define ttc (lambda (ht tva)(* ht (+ 1 (/ tva 100))) ) )ttc? (ttc 100 18.6)118.6? |
Il existe un autre moyen, surtout si on a besoin du taux de TVA en différents endroits : :
? (define tva 18.6)tva? (define ttc (lambda (ht) (* ht (+ 1 (/ tva 100)))) )ttc? (ttc 100)118.6? |
L'inconvénient de ces deux méthodes est que l'utilisateur
doit savoir comment utiliser votre fonction (mettre la tva comme deuxième
argument, ou la fixer par un define).
Il peut être préférable que le programme soit plus interactif :
? (ttc)Quel est le prix hors taxes? 100Quel est le taux de tva? 18.6118.6? |
Cela s'obtient de la manière suivante :
? (define ttc (lambda ()(let* ((bidon1 (display "Quel est le prix hors taxes? ")) (ht (read)) (bidon2 (newline))(bidon3 (display "Quel est le taux de tva? ")) (tva (read)) (bidon3 (newline))) (* ht (+ 1 (/ tva 100)))) ) ) |
Nous avons fait apparaitre trois nouvelles fonctions :
- read
(read)
Renvoie
une expression bien formée lue au clavier
Par "expression bien formée", j'entends : - Un nombre, suivi d'un retour-charriot, ou
- Une chaîne de caractères entre guillemets, suivie d'un RC, ou
- Un symbole, suivi d'un RC, ou
- Une liste, suivie d'un RC
Remarquer que read renvoie ce qu'elle a lu, pas l'évaluation de ce qu'elle a lu.
- display
(display
truc)
Affiche
sur l'écran le résultat de l'évaluation de son argument - newline
(newline)
Affiche
un retour-charriot à l'écran
13.4.
Effets de bord
La fonction ci-dessus ne se contente pas de calculer un
résultat à partir de ses arguments : elle modifie son environnement,
puisqu'elle écrit sur l'écran.
Nous avons vu, au 10.4, la
forme spéciale set! qui, elle aussi, modifie son environnement.
De telles procédures ne sont pas nécessaiement intéressantes par ce qu'elles
renvoient, mais par ce qu'elles font, d'où l'utilisation
d'identificateurs bidon dans le programme ci-dessus.
C'est ce qu'on appelle les effets de bord.
On peut être amené à enchaîner de tels effets de bord (par exemple un display
puis un newline). Ci-dessus, je l'ai fait par un let*, au prix de
l'introduction d'identificateurs bidon. Il existe un autre moyen, fourni par la
fonction begin :
![]() (begin)
(begin)
![]() Ne
fait rien! Mais puisque c'est une fonction, Scheme évalue ses arguments (dans
l'ordre) avant de l'appeler, et le tour est joué.
Ne
fait rien! Mais puisque c'est une fonction, Scheme évalue ses arguments (dans
l'ordre) avant de l'appeler, et le tour est joué.
? (define ttc (lambda ()(begin (display "Quel est le prix hors taxes? ") (let ((ht (read))) (begin (newline)(display "Quel est le taux de tva? ") (let ((tva (read)) ) (begin (newline) (* ht (+ 1 (/ tva 100)))) ) ) ) ) ) ) |
Qui peut s'écrire aussi :
? (define ttc (lambda ()(begin (display "Quel est le prix hors taxes? ") (let ((ht (read))) (begin (newline)(display "Quel est le taux de tva? ") (newline) (* ht (+ 1 (/ (read) 100)))) ) ) ) ) |
![]() Le
résultat d'un display est imprévisible. Si par exemple vous voulez
savoir ce que renvoie la fonction toto, et que vous remplacez
Le
résultat d'un display est imprévisible. Si par exemple vous voulez
savoir ce que renvoie la fonction toto, et que vous remplacez
(toto x) |
par
(display (toto x)) |
votre programme ne donnera plus le même résultat. Il faut écrire :
(begin (display (toto x))(toto x) ) |
ou, mieux
(let ((a (toto x))) (begin (display a)a )) |
13.5.
Erreurs
"Le bon programmeur n'est pas celui qui ne fait pas
d'erreur, c'est celui qui les prévoit" (proverbe silicon-valleyen).
Cas numéro 1 : on vous a donné une spécification, mais vous avez des doutes ;
par exemple, on vous demande d'écrire un programme qui travaille sur des
nombres positifs, et vous redoutez le cas où quelqu'un s'amuserait à vous
donner un nombre négatif.
Cas numéro 2 : vous êtes en cours d'écriture et vous voulez tester, mais il y a
quelques cas délicats que vous n'avez pas encore traités ; par exemple, votre
test d'arrêt n'est pas parfait, et vous ne voulez pas que la machine se lance
dans une récursion infinie si on tombe sur le cas qui n'est pas encore clair.
Cas numéro 3 : vous ne comprenez pas du tout ce qui se passe, vous souhaitez
arrêter votre programme à l'endroit où ça commence à dégénérer, pour regarder
dans quel état il erre.
La solution est apportée par la fonction error
![]() (error
"message" arg-optionnel1 arg-optionnel2 ...
arg-optionneln)
(error
"message" arg-optionnel1 arg-optionnel2 ...
arg-optionneln)
![]() Arrête
tout, affiche le message, et la valeur des arguments optionnels, puis passe
la main au debugger
Arrête
tout, affiche le message, et la valeur des arguments optionnels, puis passe
la main au debugger
Exemple :
(cond ((>= note 20) (error "Tu serais pas un peu mégalo?")) ((>= note 18) "Très bien avec félicitations du jury") ((>= note 16) "Très bien") ((>= note 14) "Bien") ((>= note 12) "Assez bien")((>= note 10) "Passable") ((>= note 0) "Same player shoots again")(else (error "Avec " note ", t'es encore plus nul que " gros-nul ", qui a obtenu " min)) ) |
13.6. trace
Lorsque vous ne
comprenez pas ce que fait votre programme, vous pouvez y introduire des display,
mais vous pouvez également utiliser la fonction trace .
(trace
nom-de-fonction)
Affiche
les paramètres d'entrée à chaque appel de fonction, et le résultat
en sortie.
trace ne prend qu'un argument, mais peut être appelée plusieurs fois.
Pour ne plus tracer, appeler (untrace) .
14-Scheme
: quelques gros trucs
14.1. apply
Je peux définir la fonction "double" par :
(define double (lambda (x) (+ x x)) ) |
la fonction "triple" par :
(define triple (lambda (x) (+ x (+ x x)) ) ) |
et d'une manière générale la fonction "plusnfois" par :
(define plusnfois (lambda (x n) (if (= n 0) x (+ x (plusnfois x (- n 1)))) ) ) |
Si maintenant je veux définir carre, puissance-3 etc, je recopie en changeant "+" en "*" :
(define multipnfois (lambda (x n) (if (= n 0) x (* x (multipnfois x (- n 1)))) ) ) |
Et si je veux un troisième opérateur... je généralise à tous les opérateurs binaires possibles :
? (define nfois (lambda (x n op) (if (= n 0)x (apply op (list x (nfois x (- n 1) op)))) ) )nfois ? (nfois 5 3 +) 20 ? (nfois 5 3 *) 625? (define plus10 (lambda (x y) (+ (+ x y) 10)) )plus10 ? (nfois 5 3 plus10) 50 ? |
![]() (apply
opérateur liste-d'arguments)
(apply
opérateur liste-d'arguments)
![]() applique
l'opérateur n-aire aux n éléments de la liste.
applique
l'opérateur n-aire aux n éléments de la liste.
14.2. map
Si je veux faire une même opération sur tous les éléments d'une liste, j'utilise la fonction map :
? (map double '(1 0 7)) (2 0 14)? |
Mais c'est vrai aussi pour les opérateurs n-aires :
? (map + '(1 0 7) '(2 5 8 10)) (3 5 15)?(define trinome (lambda (a b c x) ...trinome?(map trinome '(1 2 3 4) '(5 6 7 8) '(9 10 11 12) '(13 14 15 16)) |
![]() (map
opérateur liste1 liste2 ... listen)
(map
opérateur liste1 liste2 ... listen)
![]() applique
l'opérateur n-aire aux n cars des listes, puis aux n cadrs,
etc, en s'arrêtant à la fin de la liste la plus courte.
applique
l'opérateur n-aire aux n cars des listes, puis aux n cadrs,
etc, en s'arrêtant à la fin de la liste la plus courte.
14.3. eval
Le coeur de l'interpréteur Scheme est la fonction eval
.
![]() (eval
argument)
(eval
argument)
![]() renvoie
le résultat de l'évaluation de son argument.
renvoie
le résultat de l'évaluation de son argument.
![]() puisque
eval est une fonction, si on l'appelle au "top level", c'est-à-dire
non pas dans une fonction mais directement, ce qu'elle reçoit n'est pas son
argument, mais le résultat de l'évaluation de son argument.
puisque
eval est une fonction, si on l'appelle au "top level", c'est-à-dire
non pas dans une fonction mais directement, ce qu'elle reçoit n'est pas son
argument, mais le résultat de l'évaluation de son argument.
? (define a 'b) a? (define b 5) b? a b? (eval a) 5? |
On réalise ainsi une indirection, notion que
vous retrouverez dans d'autres langages sous le nom de pointeur.
Vous pouvez à présent vous écrire votre propre interpéteur :
(define interp (lambda () (begin(display "Que puis-je faire pour vous? ") (display (eval (read)))(newline) (interp)) ) ) |
Etonnnant, non?
Le processus s'arrête lorsqu'on évalue la fonction exit .
14.4.
Plus fort encore
apply et map sont des fonctions (et non pas
des formes spéciales), donc leur argument est évalué avant de leur être passé.
Or cet argument est un nom de fonction.
Quelle est sa valeur? C'est la liste qui commence par lambda .
Au chapitre 3.3,
nous avons dit :
Lorsqu'on lui fournit l'appel à une fonction, Scheme
- évalue chacun des arguments, dans un ordre imprévisible, PUIS
- regarde s'il connait la fonction, sinon affiche un message d'erreur
- applique la fonction aux résultats de l'évaluation des arguments
- affiche le résultat
Ce n'est pas tout à fait exact : au deuxième point, il ne
"regarde" pas ; il évalue. Le message d'erreur ne se produit que si
le résultat de l'évaluation n'est pas une lambda expression.
Cela signifie que je peux y mettre ce que je veux, du moment que le résultat de
l'évaluation est une lambda expression.
? (define machin (lambda (op arg) (op arg)) )machin? (machin plus10 5) 15? |
Il n'est même pas nécessaire de créer un symbole pour y mettre la fonction :
? (machin (lambda (a) (- a 3)) 5) 2? |
14.5.
Quelques exemples d'application
14.5.1.
Produit scalaire de deux vecteurs
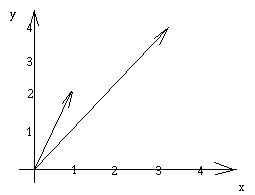
Nous souhaitons faire le produit scalaire du vecteur (1 2) et du vecteur (3 4).
Il faut multiplier les x entre eux, les y entre eux, et faire la somme :
? (apply + (map * '(1 2) '(3 4))) 11? |
Le map de * m'a fourni la liste (3 8), à laquelle
j'ai appliqué le + .
![]() Bien
faire la différence entre :
Bien
faire la différence entre :
(+ '(3 8)) , qui donnerait (3 8) ou une erreur,
et (apply + '(3 8)) , qui donne 11.
14.5.2.
Calculette pour non Schemiens
Je voudrais un programme comme cela :
? (calculette) Quelle operation voulez vous faire (+ - * /) ? + Quel est le premier nombre ? 5 Quel est le second ? 12 La reponse est 17? |
En programmation classique, j'écrirais :
(define calculette (lambda ()(let* ((bidon1 (display "Quelle operation voulez vous faire (+ - * /) ? ")) (op (read)) (bidon2 (newline))(bidon3 (display "Quel est le premier nombre ? ")) (arg1 (read)) (bidon4 (newline))(bidon5 (display "Quel est le second ? ")) (arg2 (read)) (result (cond ((equal? op '+) (+ arg1 arg2) ) ((equal? op '-) (- arg1 arg2) ) ((equal? op '*) (* arg1 arg2) ) ((equal? op '/) (/ arg1 arg2) ) (else (error "Operateur inconnu : " op)) )) ) (begin (newline) (display "La reponse est ") (display result)) ) ) ) |
En programmation avancée, j'écris :
(define calculette (lambda ()(let* ((bidon1 (display "Quelle operation voulez vous faire (+ - * / ...) ? ")) (op (read)) (bidon2 (newline))(bidon3 (display "Quel est le premier nombre ? ")) (arg1 (read)) (bidon4 (newline))(bidon5 (display "Quel est le second ? ")) (arg2 (read)) (result ((eval op) arg1 arg2)) ) (begin (newline) (display "La reponse est ")(display result) ) ) ) ) |
Remarquer que je ne suis plus limité aux 4 opérations.
Et en programmation très avancée, j'écris :
; puisque c'est toujours newline, question, reponse,; j'en fais une fonction, a laquelle il suffit de passer; le texte de la question(define question-reponse (lambda (texte)(begin (newline) (display texte) (read)) ) )(define calculette (lambda ()(let ((reps (map question-reponse (list "Quelle operation voulez vous faire (+ - * / ...) ? " "Quel est le premier nombre ? " "Quel est le second ? " ) ))) ; reps contient les trois reponses (op arg1 arg2) (begin (newline) (display "La reponse est ") (display ((eval (car reps)) (cadr reps) (caddr reps)))) ) ) ) |
Ce qui peut s'écrire encore plus simplement :
(define calculette (lambda () (let ((reps (map question-reponse (list "Quelle operation voulez vous faire (+ - * / ...) ? " "Quel est le premier nombre ? " "Quel est le second ? " ) ))) ; reps contient les trois reponses (op arg1 arg2) ; donc il suffit d'évaluer la liste(begin (newline) (display "La reponse est ") (display (eval reps)) ) ) ) ) |
14.5.3.
Méta-programmation
Supposons que la personne qui utilise le programme "calculette" s'en serve la plupart du temps pour faire la même opération, par exemple pour multiplier par 1.206 . Elle va bientôt se lasser de répondre chaque fois la même chose à deux des trois questions. Je vais donc lui écrire un programme simplifié, dérivé du précédent :
(define ttc (lambda (x)(* x 1.206) ) ) |
Supposons à présent que j'aie plein de personnes qui ont
toutes une opération simple à faire, mais que cette opération diffère d'une
personne à l'autre.
Je pourrais leur écrire à chacune un programme simple, consistant à lire la
valeur, et à lui appliquer l'opération.
Mais cela ne m'amuse pas, alors je vais leur donner à chacune un programme
unique, qui va leur créer leurs programmes :
? (make-programme) Comment voulez-vous appeler votre programme ? ttc Quel est l'operateur ? * Combien vaut la constante ? 1.206 |
Ce que je réalise de la manière suivante :
? (define make-programme (lambda ()(let* ((bidon1 (display "Comment voulez-vous appeler votre programme ? ")) (nom (read)) (bidon2 (newline))(bidon3 (display "Quel est l'operateur ? ")) (op (read)) (bidon4 (newline))(bidon5 (display "Combien vaut la constante ? ")) (const (read)) ) (eval (list'define nom (list 'lambda'(x) (list op'x const ) ; fin du programme proprement dit ) ; fin de la lambda expression ) ; fin du define ) ; allez Scheme, crée moi la fonction) ) ) make-prog |
Le programme make-prog écrit un programme, puis le
passe à Scheme qui le crée.
Essayez de faire ça dans un autre langage!
? (make-prog) Comment voulez-vous appeler votre programme ? ttc Quel est l'operateur ? * Combien vaut la constante ? 1.206 ttc? (ttc 100) 120.6? (make-prog) Comment voulez-vous appeler votre programme ? plus10 Quel est l'operateur ? + Combien vaut la constante ? 10 plus10? (plus10 5) 15? |
L'idée
sous-jacente s'appelle abstraction. Vous comparez plusieurs programmes, et mettez en
évidence ce qu'ils ont de commun dans leur structure.
Alors vous pouvez écrire un programme qui crée cette structure commune, et
prend en donnée ce qui diffère, que ce soient des constantes ou
des opérateurs.
Votre programme écrit chaque programme, et le passe à l'interpréteur Scheme,
qui ne fait pas la différence entre ce qui vient du clavier et ce qui vient
"de l'intérieur", puisque c'est la même fonction eval qui est utilisée.
15-
Ré-écriture
Peut-on faire faire des Maths à une machine? Bien sûr, à condition de savoir représenter des expressions, et de savoir représenter des "raisonnements".
15.1.
Représentation des expressions
Supposons que nous voulions dériver le trinôme. Nous écrirons :
d (ax2 + bx + c)
Cette représentation, issue d'une longue histoire, nous convient. Mais elle présente beaucoup d'inconvénients :
- Certains symboles sont implicites : vous lisez "b*x", alors que j'ai écrit "bx"
- La disposition des symboles dans l'espace revêt de l'importance : "2a" n'a pas le même sens que "2a ou a2.
- La lecture d'une telle
expression nécessite un algorithme un peu complexe, dans la mesure où il
faut attendre d'arriver au bout avant de savoir ce que représente
exactement ce que l'on lit : quand je lis "a + b", je stocke
"a" en attendant de savoir ce que je vais lui faire, je découvre
que c'est une addition, je découvre qu'il faut lui ajouter "b",
alors je le ressors...
Et quand je lis "a + ", je m'aperçois qu'il manque quelque chose, et quand je lis "a + b c", je vois qu'il y a quelque chose en trop, mais, dans les deux cas, il me faut un raisonnement un peu compliqué.
15.1.1.
Notation parenthésée
Les deux premiers points ci-dessus peuvent être satisfaits par une notation plus rigoureuse :
d ((a*(x^2)) + (b*x) + c)
C'est ce que vous écririez sous Excel, si Excel savait
dériver.
Mais ce n'est pas encore parfait, car cela suppose connue l'associativité du
symbole "+". En toute rigueur, il faudrait écrire :
d (((a*(x^2)) + (b*x)) + c)
Mais le troisième point ci-dessus subsiste : il reste difficile de déterminer si une expression est correcte, c'est-à-dire si elle n'a ni trop ni trop peu de symboles, c'est-à-dire si elle constitue un terme.
- "a + b" est un terme
- "a +" n'en est pas un
- "a + b c" non plus
15.1.2.
Notation polonaise postfixée
Cette notation est due à Jan Lucasiewicz (1878-1956). Elle consiste à :
- mettre d'abord les opérandes
- mettre ensuite l'opérateur
|
|
Ainsi, ax2 + bx + c devient : a x 2 ^ * b x * + c + |
Quel est l'intérêt? D'abord, vous constatez qu'on n'a plus
besoin de parenthèse.
Ensuite, si je veux faire un calcul numérique, je n'ai plus besoin de mettre en
réserve le premier opérande et l'opérateur binaire : les calculs se font de
gauche à droite (moyennant une pile).
Supposons par exemple que je veuille calculer la valeur de mon trinôme pour
a = 2b = 5c = 10x = 3 : a x 2 ^ * b x * + c +2 ; j'empile : 2a x 2 ^ * b x * + c + 3 ; j'empile : 2 3a x 2 ^ * b x * + c + 2 ; j'empile : 2 3 2a x 2 ^ * b x * + c + ; opérateur binaire je dépile 2 et 3, reste 2 9 ; et j'empile : 2 9a x 2 ^ * b x * + c + ; je dépile 9 et 2, reste rien 18 ; et j'empile : 18a x 2 ^ * b x * + c + 5 ; j'empile : 18 5a x 2 ^ * b x * + c + 3 ; j'empile : 18 5 3a x 2 ^ * b x * + c + ; je dépile 3 et 5, reste 18 15 ; et j'empile : 18 15a x 2 ^ * b x * + c + ; je dépile 15 et 18, reste rien 33 ; j'empile : 33a x 2 ^ * b x * + c + 10 ; j'empile : 33 10a x 2 ^ * b x * + c + ; je dépile 10 et 33, reste rien 43
Avantage : j'ai fait mon calcul de gauche à droite, donc en
O(n).
Il faut savoir que, lorsque vous utilisez un langage de programmation
"classique", la première chose que fait votre compilateur est de
transcrire vos expressions sous cette forme, car elle est optimale pour les
calculs.
Mais, ici, ce ne sont pas les calculs numériques qui nous intéressent.
15.1.3.
Notation polonaise préfixée
Renversons le principe, mettons d'abord l'opérateur et ensuite ses opérandes. L'expression ax2 + bx + c devient :
+ * a ^ x 2 + * b x c
Quel est l'intérêt? De faciliter la recherche des termes.
Pour cela, introduisons la notion d'arité : c'est le nombre
d'opérandes d'un opérateur, par exemple 2 pour + , 1 pour log , et ... 0 pour
x.
Théorème du rang : une expression est un terme si et seulement si la somme des
(arité -1) est égale à -1. Exemple : où finit le terme qui commence sur le
premier * ?
+ * a ^ x 2 + * b x c
arités : 2 2 0 2 0 0 2 2 0 0 0arités-1 : 1 1 -1 1 -1 -1 1 1 -1 -1 -1somme : 1 0 1 0 -1
Le terme est donc * a ^ x 2 .
15.1.4.
Représentation arborescente
La notation ci-dessus comporte encore une part d'implicite :
il faut un dictionnaire pour connaitre l'arité de chaque symbole.
Cela n'est plus vrai si je représente l'expression sous forme d'un arbre, dont
les sommets sont les symboles, et les arêtes les liens opérateur-opérande :
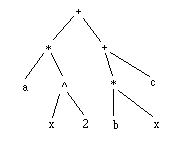
Nous avons vu au 8.2
qu'on pouvait lui substituer une représentation équivalente :
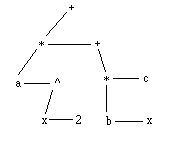
dont la représentation en machine sera :
(+ (* a (^ x 2)) (+ (* b x) c)) ... comme par hasard.
15.2.
Représentation des traitements
Comment fait on pour dériver une expression? On applique des formules :
d(U + V) = dU + dVd(U * V) = UdV + VdUd(x) = 1d(a) = 0etc.
Les informaticiens n'aiment pas le signe "=", trop vague. On lui préfèrera le signe "->", qu'on lira "se réécrit". Et les formules deviendront des règles de réécriture.
(d (+ U V)) -> (+ (d U) (d V))(d (* U V)) -> (+ (* U (d V)) (* V (d U)))(d x) -> 1(d a) -> 0
15.2.1.
Semi-unification
Comment appliquer ces règles ? On essaie d'en faire coller la partie gauche à une partie de l'énoncé :
Enoncé : (d (+ (* a (^ x 2)) (+ (* b x) c)))Règle : (d (+ U V )
On voit tout de suite l'intérêt de savoir trouver facilement
les termes. Cette opération fait apparaitre le rôle différent de certains
symboles : pour d, +, il faut une exacte correspondance, sinon on
essaie une autre règle, ou la même règle en un autre endroit.
Pour U et V, en revanche, il faut et il suffit qu'on puisse leur
substituer un terme ; on les appelle des substituables (et non
des variables, puisqu'ils ne varient pas).
L'opération consistant à se promener en parallèle dans l'énoncé et dans la
partie gauche de la règle, en faisant coller les symboles, s'appelle le pattern
matching, ou semi-unification (on parle d'unification si les deux expressions
contiennent des substituables).
Elle suppose que l'on tienne à jour une table des substitutions.
15.2.2.
Réécriture
Si l'on arrive sans échec à unifier la partie gauche de la règle avec une portion de l'énoncé, on peut réécrire, en utilisant la partie droite et la table :
U -> (* a (^ x 2))V -> (+ (* b x) c))(+ (d U) (d V)) -> (+ (d (* a (^ x 2))) (d (+ (* b x) c)))
On est ici dans le cas particulier où la partie gauche s'est
unifiée avec l'énoncé complet.
Ensuite on recommence :
(+ (d (* a (^ x 2))) (d (+ (* b x) c)))(d
Echec. On essaie les autres règles, elles échouent toutes. On essaie alors ailleurs :
(+ (d (* a (^ x 2))) (d (+ (* b x) c)))(d (+
échec(+ (d (* a (^ x 2))) (d (+ (* b x) c)))(d (* U V )
succès, on réécrit :(+ (+ (* a (d (^ x 2))) (* (^ x 2) (d a))) (d (+ (* b x) c)))--- U dV V dU ------------------
Et ainsi de suite, jusqu'à ce que plus aucune règle ne s'applique.
(+ (+ (* a (d (^ x 2))) (* (^ x 2) (d a))) (d (+ (* b x) c))) d ^ U N(+ (+ (* a (* 2 (* (^ x (- 2 1)) (d x)))) (* (^ x 2) (d a))) (d (+ (* b x) c))) d x(+ (+ (* a (* 2 (* (^ x (- 2 1)) 1))) (* (^ x 2) (d a))) (d (+ (* b x) c))) d a(+ (+ (* a (* 2 (* (^ x (- 2 1)) 1))) (* (^ x 2) 0)) (d (+ (* b x) c)))d + U V
(+ (+ (* a (* 2 (* (^ x (- 2 1)) 1))) (* (^ x 2) 0)) (+ (d (* b x)) (d c))) d * U V(+ (+ (* a (* 2 (* (^ x (- 2 1)) 1))) (* (^ x 2) 0)) (+ (+ (* b (d x)) (* x (d b))) (d c))) d x(+ (+ (* a (* 2 (* (^ x (- 2 1)) 1))) (* (^ x 2) 0)) (+ (+ (* b 1) (* x (d b))) (d c))) d b(+ (+ (* a (* 2 (* (^ x (- 2 1)) 1))) (* (^ x 2) 0)) (+ (+ (* b 1) (* x 0)) (d c))) d c(+ (+ (* a (* 2 (* (^ x (- 2 1)) 1))) (* (^ x 2) 0)) (+ (+ (* b 1) (* x 0)) 0))
C'est correct, mais pas joli. Donc j'ajoute les règles de description des particularités du Corps des Réels :
(* U 0) -> 0(* 0 U) -> 0(* U 1) -> U(* 1 U) -> U(+ U 0) -> U(+ 0 U) -> U
Remarquez que je ne peux pas traduire la commutativité par
des règles.
On repart :
(+ (+ (* a (* 2 (* (^ x (- 2 1)) 1))) (* (^ x 2) 0)) (+ (+ (* b 1) (* x 0)) 0)) * U 1
(+ (+ (* a (* 2 (^ x (- 2 1)))) (* (^ x 2) 0)) (+ (+ (* b 1) (* x 0)) 0)) * U 0(+ (+ (* a (* 2 (^ x (- 2 1)))) 0) (+ (+ (* b 1) (* x 0)) 0))+ U 0
(+ (* a (* 2 (^ x (- 2 1)))) (+ (+ (* b 1) (* x 0)) 0)) * U 1(+ (* a (* 2 (^ x (- 2 1)))) (+ (+ b (* x 0)) 0))* U 0
(+ (* a (* 2 (^ x (- 2 1)))) (+ (+ b 0) 0)) + U 0(+ (* a (* 2 (^ x (- 2 1)))) (+ b 0)) + U 0
(+ (* a (* 2 (^ x (- 2 1)))) b)
On a presque fini. Pour que ce soit parfait, il faudrait que j'ajoute la règle :
(- 2 1) -> 1
Mais là, je mets le doigt dans l'engrenage :
(- 3 1) -> 2(- 3 2) -> 1...(- 257 15) -> 242...
On aboutit alors à ce paradoxe, que mon système sait faire
de la dérivation formelle (considérée par les élèves comme un peu compliquée),
et ne sait pas faire de calcul numérique (considéré comme simple).
Ce n'est pas grave, car le calcul numérique est câblé dans la machine : il
suffit d'ajouter un petit module :
(if (and (= (length liste) 3) (number? (cadr liste))(number? (caddr liste)) ) (apply (car liste) (cdr liste)) liste) |
15.3.
Beauté et limites
15.3.1.
Désordre
L'ordre dans lequel sont écrites les règles n'influe en rien le résultat, et à peine sur le temps de calcul. On peut donc les écrire au fur et à mesure qu'on découvre qu'il en manque.
15.3.2.
Maintenance
Lorsque le système produit un résultat faux :
- Il est facile de lui demander comment il l'a obtenu
- Grace au désordre, il est facile de corriger : on enlève la mauvaise et on ajoute les bonnes n'importe où
15.3.3.
Langage
Le langage d'expression des règles (moyennant une petite interface de traduction parenthésée -> listes) est utilisable par n'importe qui, sans formation à l'Informatique. L'écriture et la maintenance du système ne requièrent donc pas de compétence spéciale.
15.3.4.
Généralité
L'algorithme qui applique les règles de réécriture à l'énoncé n'a absolument aucune connaissance du problème traité. Il est universel. Je peux enlever cette base de règles et en mettre une autre, par exemple :
le -> the loup -> wolfet -> andl' -> theagneau -> lamb
... et j'ai un système de traduction automatique (je
plaisante).
En d'autres termes, si je sais représenter mon raisonnement par des règles de
réécriture, je n'ai plus besoin de programmer, il suffit d'écrire les règles.
Mais
L'algorithme termine lorsque plus aucune règle ne s'applique. Cela impose des conditions sur les règles.
15.3.5.
Possibilités de bouclage
Si vous avez fait un peu de trigonométrie, vous vous souvenez de la règle
sin2x + cos2x -> 1
Si vous avez fait un peu plus de trigo, vous vous souvenez qu'on utilise aussi la règle
1 -> sin2x + cos2x
Il est possible à l'algorithme de boucler, en appliquant
alternativement la première et la deuxième.
Premier théorème de Fouet : si un algorithme peut boucler, il bouclera.
15.3.6.
Possibilités d'explosion
Si vous avez fait beaucoup de trigo, vous savez que, pour utiliser la deuxième règle ci-dessus, on utilise souvent la règle
U -> U * 1
Cette règle peut s'appliquer à son propre résultat, donnant
U * 1 * 1 , puis U * 1 * 1 * 1,... jusqu'au stack overflow.
Deuxième théorème de Fouet : vous m'avez compris
15.3.7.
Stratégie
Si ces règles sont laissées sans surveillance, on n'est pas
sûr d'obtenir le résultat en temps fini, soit parce que ça boucle, soit parce
que cela explose. Il faut donc mettre en place une surveillance, qui leur
interdit de s'appliquer "à tort et à travers".
L'ennui, c'est que cette stratégie peut parfois empècher l'application d'une
règle alors qu'il le faudrait.
Troisième théorème (mais il n'est pas de moi) : il n'existe aucune
stratégie qui garantisse qu'on ne passera pas à côté du résultat.
On n'est pas sûr d'obtenir le résultat en temps fini,
- soit parce que ça boucle,
- soit parce que cela explose,
- soit parce que le système s'arrête, alors qu'il n'a pas fini.
Index
|
abstraction |
|
|
adresse |
|
|
algorithme |
|
|
alpha-beta |
|
|
append |
|
|
apply |
|
|
arbre |
|
|
argument |
|
|
ASCII |
|
|
begin |
|
|
bit |
|
|
bloc |
|
|
bug |
|
|
car |
|
|
cdr |
|
|
codage |
|
|
commentaires |
|
|
complexité |
|
|
cond |
|
|
cons |
|
|
define |
|
|
display |
|
|
effets de bord |
|
|
entrées/sorties |
|
|
eq? |
|
|
error |
|
|
eval |
|
|
évaluation |
|
|
fichier |
|
|
faux |
|
|
fonction |
|
|
forme spéciale |
|
|
heuristique |
|
|
Huffman |
|
|
indentation |
|
|
input |
|
|
identificateur
|
|
|
if |
|
|
itération |
|
|
jeu d'essai |
|
|
jeux |
|
|
lambda |
|
|
largeur d'abord |
|
|
length |
|
|
let |
|
|
let* |
|
|
list |
|
|
liste |
|
|
list-ref |
|
|
list? |
|
|
map |
|
|
mémoire |
|
|
minimax |
|
|
modèles de données |
|
|
mot |
|
|
newline |
|
|
null? |
|
|
octet |
|
|
output |
|
|
pile |
|
|
pop |
|
|
prédicat |
|
|
préfixe |
|
|
profondeur d'abord |
|
|
prompt |
|
|
push |
|
|
quote |
|
|
quotient |
|
|
read |
|
|
récursion |
|
|
ré-écriture |
|
|
répertoire |
|
|
set! |
|
|
spécification |
|
|
terme |
|
|
trace |
|
|
tris |
|
|
type |
|
|
untrace |
|
|
vrai |
|
|
= |
|
|
< |
|
|
#f |
|
|
#t |
|
|
' |
|
|
/ |